Daten in verteilten Datenbanken löschen
Long story, short...
Man nehme...
DELETE * FROM [TABLE] WHERE ...
… und schon sind die Daten gelöscht.
Fertig ist der Blog-Beitrag!
Gemach, Gemach, ganz so einfach ist es sicherlich nicht, wenn es um das Löschen von Daten aus verteilten Datenbanken geht.
Im vorangegangenen Kapitel habe ich beschrieben, wie in verteilten Datenspeichern Daten, quorumbasiert, gelesen und geschrieben werden.
Was aber passiert beim Löschen von Daten aus verteilten Systemen?
Grundsätzlich wird beim löschen von Informationen aus einem verteilten Datenspeicher das gleiche, quorumbasierte, Prinzip angewandt. Allerdings bringt dieses Prinzip, technisch bedingt ein Problem mit sich.
Der einfache Fall
Fangen wir mit dem einfachsten Beispiel an.
Irgendwann wurde in eine Tabelle eine Nachricht mit der Id = 1 und einem Replication Factor 3 geschrieben. Der Datensatz wurde im Laufe der Zeit auf 2 weitere Nodes im Cluster repliziert, so dass für diese Nachricht der Zustand im Cluster konsistent ist.
Diese Nachricht wird nun nicht mehr benötigt und soll gelöscht werden. Der Server-Cluster sowie alle Nodes sind up and running, alles fein soweit.
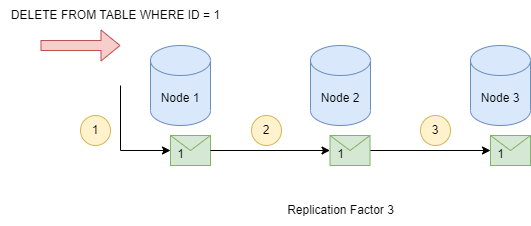
Das DELETE Statement wird abgesetzt und der Koordinator-Node nimmt das Statement entgegen.
Aus dem zu löschenden Datensatz mit der Id 1 wird der Hashwert gebildet und innerhalb des Cassandra-Clusters ist die Position bekannt an der dieser Datensatz abgelegt ist.
Da für diese Tabelle der Replication-Factor eingerichtet ist, weiß der Koordinator das noch 2 andere Replikas (vor und nach dem Node mit dem initialen Datensatz) im System vorhanden sein müssen und sendet das DELETE-Statement weiter.
In Abhängigkeit vom eingestellten Konsistenzlevel wird, bei erfolgreicher Löschung dem Client der Status zurückgemeldet.
Bei QUORUM:
Sobald die Mehrzahl der Nodes den Lösch-Vorgang erfolgreich gemeldet haben, meldet der Koordinator-Node an den Client (der das DELETE-Statement abgesetzt hat) zurück, dass die Nachricht mit der ID 1 mit Quorum gelöscht wurde, was heißt, dass die Mehrzahl der Nodes den Löschvorgang durchgeführt und bestätigt haben.
Bei ONE:
Wenigstens ein Node hat die Löschung durchgeführt (der Koordinator).
Bei ALL:
Alles Nodes müssen die Löschung des Datensatzes bestätigen.
Dieses Beispiel beschreibt den Löschvorgang eher aus fachlicher Sicht.
Aber was bedeutet eigentlich „Löschen von Daten in Cassandra“ und was passiert hier innerhalb der Datenbank?
Was passiert beim löschen von Datensätzen in Cassandra technisch?
Was heißt eigentlich Löschen in verteilten Datenspeichern wie Apache Cassandra?
Wenn die Nachricht mit der Id = 1 gelöscht wird, ist dies kein physikalischer Löschvorgang. Es ist auch kein logisches Löschen, wie es verschiedene Betriebssysteme tun (Ändern des gelöschten Dateinamen durch Austausch des 1. Buchstaben mit einem Fragezeichen).
Man muss sich die Vorgänge in diesem Speichersystem wie einen Stack vorstellen. Änderungen an einem Datensatz werden im wahrsten Sinne, nur auf die vorherige Änderung des Datensatzes zugefügt.

Der Löschvorgang in Cassandra wird, als neue Version für diese Tabelle dem Dateisystem hinzugefügt.
Werden jetzt Datensätze aus dieser Tabelle mit Cassandra gelesen, werden alle Shards der angeforderten Zeilen, aus den Memtables und den SSTables zusammengeführt. Anschließend wird ein Last-Write-Wins Algorithmus angewandt um die, zeitlich korrekten Versionen, des Datensatzes auszuwählen unabhängig davon, ob es sich um einen regulären Datensatz oder einen Tombstone handelt. Diese Nachrichtenfragmente werden zusammengeführt (merge) und zurückgegeben.
Letztendlich ist in Cassandra eine Löschung gleichwertig wie ein Update-Statement, so dass beim Lesen eines Datensatzes immer von der ältesten bist zur neuesten Version eines Datensatzes gelesen und zusammengeführt wird.
Ist die aktuellste Version eines Datensatzes ein Löschvorgang, werden (aus logischer Sicht) alle älteren Vorgänge „umsonst“ zusammengeführt.
Löschen von Nachrichten in der Praxis
In den folgenden Beispielen wird demonstriert, wie das fachliche Löschen von Datensätzen in der Cassandra-Datenbank funktioniert.
Ausgehend von unserem Testcluster aus Kapitel 2 bzw. Kapitel 1 (für den Aufbau), wird das Löschen von Datensätzen im folgenden demonstriert.
Der Cassandra-Cluster ist gestartet, wir haben einen Keyspace testkeyspace und eine Tabelle testtable mit folgenden Werten angelegt.
cqlsh:testkeyspace> DESC TABLE testtable ;
CREATE TABLE testkeyspace.testtable (
id int PRIMARY KEY,
firstname text,
lastname text
) WITH bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
Das Dateisystem für diese Tabelle ist leer.
Wir fügen jetzt einen Datensatz in die Tabelle ein und wenden den Befehl nodetool flush an, um den Datensatz von der Memtable in die unveränderliche SSTable auf Disk zu überführen.
cqlsh:testkeyspace> INSERT INTO testtable (id , firstname , lastname ) VALUES ( 1, 'anna', 'schmidt');
cqlsh:testkeyspace> select * from testtable ;
id | firstname | lastname
----+-----------+----------
1 | anna | schmidt
(1 rows)
root@a0617040d7df:/var/lib/cassandra/data/testkeyspace/testtable-1fcaeb7095a811ed81e369687072559d# nodetool flush
root@a0617040d7df:/var/lib/cassandra/data/testkeyspace/testtable-1fcaeb7095a811ed81e369687072559d# ls -lah
total 8.0K
drwxr-xr-x 1 cassandra cassandra 512 Jan 16 14:19 .
drwxr-xr-x 1 cassandra cassandra 512 Jan 16 14:14 ..
drwxr-xr-x 1 cassandra cassandra 512 Jan 16 14:14 backups
-rw-r--r-- 1 cassandra cassandra 43 Jan 16 14:19 me-1-big-CompressionInfo.db
-rw-r--r-- 1 cassandra cassandra 45 Jan 16 14:19 me-1-big-Data.db
-rw-r--r-- 1 cassandra cassandra 9 Jan 16 14:19 me-1-big-Digest.crc32
-rw-r--r-- 1 cassandra cassandra 16 Jan 16 14:19 me-1-big-Filter.db
-rw-r--r-- 1 cassandra cassandra 8 Jan 16 14:19 me-1-big-Index.db
-rw-r--r-- 1 cassandra cassandra 4.7K Jan 16 14:19 me-1-big-Statistics.db
-rw-r--r-- 1 cassandra cassandra 56 Jan 16 14:19 me-1-big-Summary.db
-rw-r--r-- 1 cassandra cassandra 92 Jan 16 14:19 me-1-big-TOC.txt
Diesen Datensatz werden wir jetzt löschen und die Situation sowohl aus fachlicher Sicht, als auch aus technischer Sicht betrachten.
cqlsh:testkeyspace> DELETE FROM testtable where id = 1;
cqlsh:testkeyspace> select * from testtable ;
id | firstname | lastname
----+-----------+----------
(0 rows)
root@a0617040d7df:/var/lib/cassandra/data/testkeyspace/testtable-1fcaeb7095a811ed81e369687072559d# nodetool flush
root@a0617040d7df:/var/lib/cassandra/data/testkeyspace/testtable-1fcaeb7095a811ed81e369687072559d# ls -lah
total 16K
drwxr-xr-x 1 cassandra cassandra 512 Jan 16 14:21 .
drwxr-xr-x 1 cassandra cassandra 512 Jan 16 14:14 ..
drwxr-xr-x 1 cassandra cassandra 512 Jan 16 14:14 backups
-rw-r--r-- 1 cassandra cassandra 43 Jan 16 14:19 me-1-big-CompressionInfo.db
-rw-r--r-- 1 cassandra cassandra 45 Jan 16 14:19 me-1-big-Data.db
-rw-r--r-- 1 cassandra cassandra 9 Jan 16 14:19 me-1-big-Digest.crc32
-rw-r--r-- 1 cassandra cassandra 16 Jan 16 14:19 me-1-big-Filter.db
-rw-r--r-- 1 cassandra cassandra 8 Jan 16 14:19 me-1-big-Index.db
-rw-r--r-- 1 cassandra cassandra 4.7K Jan 16 14:19 me-1-big-Statistics.db
-rw-r--r-- 1 cassandra cassandra 56 Jan 16 14:19 me-1-big-Summary.db
-rw-r--r-- 1 cassandra cassandra 92 Jan 16 14:19 me-1-big-TOC.txt
-rw-r--r-- 1 cassandra cassandra 43 Jan 16 14:21 me-2-big-CompressionInfo.db
-rw-r--r-- 1 cassandra cassandra 29 Jan 16 14:21 me-2-big-Data.db
-rw-r--r-- 1 cassandra cassandra 10 Jan 16 14:21 me-2-big-Digest.crc32
-rw-r--r-- 1 cassandra cassandra 16 Jan 16 14:21 me-2-big-Filter.db
-rw-r--r-- 1 cassandra cassandra 8 Jan 16 14:21 me-2-big-Index.db
-rw-r--r-- 1 cassandra cassandra 4.6K Jan 16 14:21 me-2-big-Statistics.db
-rw-r--r-- 1 cassandra cassandra 56 Jan 16 14:21 me-2-big-Summary.db
-rw-r--r-- 1 cassandra cassandra 92 Jan 16 14:21 me-2-big-TOC.txt
Ganz klar erkennbar ist, dass der Eintrag für den geschriebenen Datensatz me-1-* als unveränderlicher Eintrag im System vorhanden ist. Das Löschen der Nachricht wurde als weitere SSTable aufgenommen. Mit dem Befehl sstabledump schauen wir uns die Löschung einmal genauer an.
root@a0617040d7df:/var/lib/cassandra/data/testkeyspace/testtable-1fcaeb7095a811ed81e369687072559d# /opt/cassandra/tools/bin/sstabledump me-2-big-Data.db
[
{
"partition" : {
"key" : [ "1" ],
"position" : 0,
"deletion_info" : { "marked_deleted" : "2023-01-16T14:21:13.961540Z", "local_delete_time" : "2023-01-16T14:21:13Z" }
},
"rows" : [ ]
}
]
Der Datensatz mit der Id 1 (Key) wurde am 16.01.23 14:21…. zur Löschung markiert. Was besagt, dass dieser Eintrag nicht gelöscht wurde. Was ja auch stimmt, die SSTable ist ja nach wie vor im Dateisystem vorhanden.
Bei der SELECT ... Abfrage werden alle SSTables zu diesem Datensatz zusammengefasst. Die letzte Version dieses Datensatzes ist die Löschung, also wird der Merge durchgeführt und direkt verworfen.
Daher kann es sehr wohl zu einem Performance-Problemen kommen, wenn häufig geänderte Datensätze gelöscht werden, solange ein nodetool compact nicht ausgeführt wurde.
Wenn man jetzt versucht einen bereits gelöschten Datensatz „widerherzustellen“, indem man einfach ein UPDATE Statement darauf ausführt, wird enttäuscht werden.
Anders jedoch, als bei RDBMS, bei dem das folgende Statement fehlschlagen muss, ist das für Cassandra kein Problem, es setzt den fehlenden Wert einfach auf null.
cqlsh:testkeyspace> UPDATE testtable set lastname = 'wolf' where id = 1;
cqlsh:testkeyspace> select * from testtable ;
id | firstname | lastname
----+-----------+----------
1 | null | wolf
(1 rows)
Im Dateisystem wurde für den neuen Datensatz ein neuer Eintrag me-3-* angelegt.
Wir haben ja erfahren dass die SSTables, also die Änderungen an den Datensätzen, unveränderlich sind. Was passiert also, wenn man einen gelöschten Datensatz noch einmal löscht? Also das folgende Szenario:
cqlsh:testkeyspace> INSERT INTO testtable (id , firstname , lastname ) VALUES ( 1, 'anna', 'schmidt');
nodetool flush
cqlsh:testkeyspace> DELETE FROM testtable where id = 1;
nodetool flush;
cqlsh:testkeyspace> DELETE FROM testtable where id = 1;
nodetool flush;
Wer jetzt vermutet hat, dass auf Grund der Unveränderlichkeit der SSTables einfach eine neue SSTable für jeden Löscheintrag erzeugt wird, hat leider Recht. Jeder Löschvorgang, der außerhalb der Memtables durchgeführt wird ist ebenso immutable wie eine Aktualsierung (Update) außerhalb der Memtables.
Würde man das nodetool flush an der Stelle weglassen, würde nichts passieren, da das Insert, Update und die Löschung in der Memtable einfach ausgeführt wird, da diese ja mutable sind.
root@a0617040d7df:/var/lib/cassandra/data/testkeyspace/testtable-1fcaeb7095a811ed81e369687072559d# ls -lah
total 24K
drwxr-xr-x 1 cassandra cassandra 512 Jan 16 14:46 .
drwxr-xr-x 1 cassandra cassandra 512 Jan 16 14:14 ..
drwxr-xr-x 1 cassandra cassandra 512 Jan 16 14:14 backups
-rw-r--r-- 1 cassandra cassandra 51 Jan 16 14:45 me-6-big-CompressionInfo.db
-rw-r--r-- 1 cassandra cassandra 60 Jan 16 14:45 me-6-big-Data.db
-rw-r--r-- 1 cassandra cassandra 8 Jan 16 14:45 me-6-big-Digest.crc32
-rw-r--r-- 1 cassandra cassandra 16 Jan 16 14:45 me-6-big-Filter.db
-rw-r--r-- 1 cassandra cassandra 8 Jan 16 14:45 me-6-big-Index.db
-rw-r--r-- 1 cassandra cassandra 4.7K Jan 16 14:45 me-6-big-Statistics.db
-rw-r--r-- 1 cassandra cassandra 56 Jan 16 14:45 me-6-big-Summary.db
-rw-r--r-- 1 cassandra cassandra 92 Jan 16 14:45 me-6-big-TOC.txt
-rw-r--r-- 1 cassandra cassandra 43 Jan 16 14:45 me-7-big-CompressionInfo.db
-rw-r--r-- 1 cassandra cassandra 29 Jan 16 14:45 me-7-big-Data.db
-rw-r--r-- 1 cassandra cassandra 10 Jan 16 14:45 me-7-big-Digest.crc32
-rw-r--r-- 1 cassandra cassandra 16 Jan 16 14:45 me-7-big-Filter.db
-rw-r--r-- 1 cassandra cassandra 8 Jan 16 14:45 me-7-big-Index.db
-rw-r--r-- 1 cassandra cassandra 4.6K Jan 16 14:45 me-7-big-Statistics.db
-rw-r--r-- 1 cassandra cassandra 56 Jan 16 14:45 me-7-big-Summary.db
-rw-r--r-- 1 cassandra cassandra 92 Jan 16 14:45 me-7-big-TOC.txt
-rw-r--r-- 1 cassandra cassandra 43 Jan 16 14:46 me-8-big-CompressionInfo.db
-rw-r--r-- 1 cassandra cassandra 29 Jan 16 14:46 me-8-big-Data.db
-rw-r--r-- 1 cassandra cassandra 10 Jan 16 14:46 me-8-big-Digest.crc32
-rw-r--r-- 1 cassandra cassandra 16 Jan 16 14:46 me-8-big-Filter.db
-rw-r--r-- 1 cassandra cassandra 8 Jan 16 14:46 me-8-big-Index.db
-rw-r--r-- 1 cassandra cassandra 4.6K Jan 16 14:46 me-8-big-Statistics.db
-rw-r--r-- 1 cassandra cassandra 56 Jan 16 14:46 me-8-big-Summary.db
-rw-r--r-- 1 cassandra cassandra 92 Jan 16 14:46 me-8-big-TOC.txt
Kurze Erläuterung zu Drop-Table- und Truncate-Table-Statements
Sowohl DROP TABLE testtable; als auch TRUNCATE TABLE testtable; verwerfen grundsätzlich die jeweiligen Tabellen (fachlich), aber es wird von der zu löschenden Tabelle ein Snapshot der zuletzt gespeicherten Datensätze aufgehoben. Dies ist zu berücksichtigen, falls man sich wundert, dass nach einem solchen Vorgang nicht genügend Speicherkapazität frei wird.
Snapshots werden auch nicht mehr durch den Befehl nodetool compact berücksichtigt. Das bedeutet, dass man für erheblich mehr Speicherplatz im Dateisystem sorgen kann, wenn man vor einem TRUNCATE TABLE ... oder DROP TABLE ... ein nodetool compact durchführt.
Beispiel (bitte den Verzeichniswechsel beachten nach ./snapshots/truncated-...):
cqlsh:testkeyspace> TRUNCATE TABLE testtable ;
root@a0617040d7df:/var/lib/cassandra/data/testkeyspace/testtable-1fcaeb7095a811ed81e369687072559d/snapshots/truncated-1673880698401-testtable# ls -lah
total 28K
drwxr-xr-x 1 cassandra cassandra 512 Jan 16 14:51 .
drwxr-xr-x 1 cassandra cassandra 512 Jan 16 14:51 ..
-rw-r--r-- 1 cassandra cassandra 69 Jan 16 14:51 manifest.json
-rw-r--r-- 1 cassandra cassandra 51 Jan 16 14:45 me-6-big-CompressionInfo.db
-rw-r--r-- 1 cassandra cassandra 60 Jan 16 14:45 me-6-big-Data.db
-rw-r--r-- 1 cassandra cassandra 8 Jan 16 14:45 me-6-big-Digest.crc32
-rw-r--r-- 1 cassandra cassandra 16 Jan 16 14:45 me-6-big-Filter.db
-rw-r--r-- 1 cassandra cassandra 8 Jan 16 14:45 me-6-big-Index.db
-rw-r--r-- 1 cassandra cassandra 4.7K Jan 16 14:45 me-6-big-Statistics.db
-rw-r--r-- 1 cassandra cassandra 56 Jan 16 14:45 me-6-big-Summary.db
-rw-r--r-- 1 cassandra cassandra 92 Jan 16 14:45 me-6-big-TOC.txt
-rw-r--r-- 1 cassandra cassandra 43 Jan 16 14:45 me-7-big-CompressionInfo.db
-rw-r--r-- 1 cassandra cassandra 29 Jan 16 14:45 me-7-big-Data.db
-rw-r--r-- 1 cassandra cassandra 10 Jan 16 14:45 me-7-big-Digest.crc32
-rw-r--r-- 1 cassandra cassandra 16 Jan 16 14:45 me-7-big-Filter.db
-rw-r--r-- 1 cassandra cassandra 8 Jan 16 14:45 me-7-big-Index.db
-rw-r--r-- 1 cassandra cassandra 4.6K Jan 16 14:45 me-7-big-Statistics.db
-rw-r--r-- 1 cassandra cassandra 56 Jan 16 14:45 me-7-big-Summary.db
-rw-r--r-- 1 cassandra cassandra 92 Jan 16 14:45 me-7-big-TOC.txt
-rw-r--r-- 1 cassandra cassandra 43 Jan 16 14:46 me-8-big-CompressionInfo.db
-rw-r--r-- 1 cassandra cassandra 29 Jan 16 14:46 me-8-big-Data.db
-rw-r--r-- 1 cassandra cassandra 10 Jan 16 14:46 me-8-big-Digest.crc32
-rw-r--r-- 1 cassandra cassandra 16 Jan 16 14:46 me-8-big-Filter.db
-rw-r--r-- 1 cassandra cassandra 8 Jan 16 14:46 me-8-big-Index.db
-rw-r--r-- 1 cassandra cassandra 4.6K Jan 16 14:46 me-8-big-Statistics.db
-rw-r--r-- 1 cassandra cassandra 56 Jan 16 14:46 me-8-big-Summary.db
-rw-r--r-- 1 cassandra cassandra 92 Jan 16 14:46 me-8-big-TOC.txt
-rw-r--r-- 1 cassandra cassandra 857 Jan 16 14:51 schema.cql
Daten löschen mittels TTL
In Cassandra gibt es die Möglichkeit, bei der Erstellung einer Tabelle, eine Option für eine TTL (Time to Live) der Datensätze zu speichern.
Das bedeutet, jede Nachricht wird, sobald die TTL erreicht ist aus der Tabelle gelöscht?
Nein, das ist falsch!
Die Datenlöschung mittels TTL wird anhand eines Beispiels erklärt.
Eine Tabelle deren Datensätze mit TTL geschrieben werden, wird mit einem zusätzlichen Parameter angelegt.
cqlsh:testkeyspace> CREATE TABLE testtablettl ( id int PRIMARY KEY , firstname text , lastname text ) WITH default_time_to_live = 120;
Der Wert für default_time_to_live ist in Sekunden angegeben. Für das obige Beispiel gilt eine Time to live für einen Datensatz von 120 Sekunden.
Mittels desc TABLE testtablettl können wir, nachträglich prüfen, wie die Tabelle designed ist (und sehen im nachfolgenden Beispiel, dass der Wert für default_time_to_live gesetzt wurde.
cqlsh:testkeyspace> desc TABLE testtablettl
CREATE TABLE testkeyspace.testtablettl (
id int PRIMARY KEY,
firstname text,
lastname text
) WITH bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 120
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
Im Dateisystem sind keinerlei Einträge zu dieser Tabelle vorhanden, da ja noch keine Daten geschrieben wurden. Dies werden wir jetzt tun.
Wir legen zuerst einen Datensatz an und prüfen ob die Daten ordnungsgemäß in die Tabelle geschrieben wurden.
cqlsh:testkeyspace> INSERT INTO testtablettl (id , firstname , lastname ) VALUES ( 1, 'Willy', 'Meier');
cqlsh:testkeyspace> select * from testtablettl;
id | firstname | lastname
----+-----------+----------
1 | Willy | Meier
(1 rows)
Im Dateisystem führen wir erst den Befehl nodetool flush aus und prüfen die Informationen die jetzt im Dateisystem gespeichert wurden.
root@a0617040d7df:/var/lib/cassandra/data/testkeyspace/testtablettl-115d708095bc11ed81e369687072559d# nodetool flush
root@a0617040d7df:/var/lib/cassandra/data/testkeyspace/testtablettl-115d708095bc11ed81e369687072559d# ls -lah
total 8.0K
drwxr-xr-x 1 cassandra cassandra 512 Jan 20 10:22 .
drwxr-xr-x 1 cassandra cassandra 512 Jan 16 16:37 ..
drwxr-xr-x 1 cassandra cassandra 512 Jan 16 16:37 backups
-rw-r--r-- 1 cassandra cassandra 43 Jan 20 10:22 me-1-big-CompressionInfo.db
-rw-r--r-- 1 cassandra cassandra 46 Jan 20 10:22 me-1-big-Data.db
-rw-r--r-- 1 cassandra cassandra 9 Jan 20 10:22 me-1-big-Digest.crc32
-rw-r--r-- 1 cassandra cassandra 16 Jan 20 10:22 me-1-big-Filter.db
-rw-r--r-- 1 cassandra cassandra 8 Jan 20 10:22 me-1-big-Index.db
-rw-r--r-- 1 cassandra cassandra 4.7K Jan 20 10:22 me-1-big-Statistics.db
-rw-r--r-- 1 cassandra cassandra 56 Jan 20 10:22 me-1-big-Summary.db
-rw-r--r-- 1 cassandra cassandra 92 Jan 20 10:22 me-1-big-TOC.txt
Offensichtlich wurde der Datensatz in die Verzeichnisstruktur geschrieben. Das prüfen wir mit dem Tool sstabledump.
root@a0617040d7df:/var/lib/cassandra/data/testkeyspace/testtablettl-115d708095bc11ed81e369687072559d# /opt/cassandra/tools/bin/sstabledump me-1-big-Data.db
[
{
"partition" : {
"key" : [ "1" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 18,
"liveness_info" : { "tstamp" : "2023-01-20T10:22:38.764085Z", "ttl" : 120, "expires_at" : "2023-01-20T10:24:38Z", "expired" : false },
"cells" : [
{ "name" : "firstname", "value" : "Willy" },
{ "name" : "lastname", "value" : "Meier" }
]
}
]
}
]
Bei der Betrachtung der Daten fällt auf, dass gegenüber dem einfachen Schreiben von Daten (ohne TTL) Metainformationen hinzugefügt wurden. In der Zeile
"liveness_info" : { "tstamp" : "2023-01-20T10:22:38.764085Z", "ttl" : 120, "expires_at" : "2023-01-20T10:24:38Z", "expired" : false }
stehen die TTL-Informationen für diesen Datensatz. Nach 2 Minuten Wartezeit, überprüfen wir die Tabelle zuerst aus fachlicher Sicht mit einem SELECT-Statement.
cqlsh:testkeyspace> select * from testtablettl;
id | firstname | lastname
----+-----------+----------
(0 rows)
Wie zu erwarten war, ist der Datensatz, fachlich, nicht mehr verfügbar. Jetzt prüfen wir noch die Tabellenstruktur mit dem Tool sstabledump.
root@a0617040d7df:/var/lib/cassandra/data/testkeyspace/testtablettl-115d708095bc11ed81e369687072559d# /opt/cassandra/tools/bin/sstabledump me-1-big-Data.db
[
{
"partition" : {
"key" : [ "1" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 18,
"liveness_info" : { "tstamp" : "2023-01-20T10:22:38.764085Z", "ttl" : 120, "expires_at" : "2023-01-20T10:24:38Z", "expired" : true },
"cells" : [
{ "name" : "firstname", "value" : "Willy" },
{ "name" : "lastname", "value" : "Meier" }
]
}
]
}
]
Wir sehen sehr deutlich, dass der Eintrag nach wie vor, mit Daten, in der Tabelle steht.
Es wurde also nichts gelöscht!
Einzig der Eintrag "expired": true ist geändert, was Cassandra dazu veranlasst, diesen Datensatz nicht mehr zu berücksichtigen.
Jetzt könnte man natürlich meinen, dass hier ein Fehler in Cassandra aufgetreten ist, da eine SSTable in Cassandra eigentlich unveränderlich ist und hier ganz eindeutig eine bestehende Datei, nachträglich verändert wurde (das setzen von false auf true).
Das stimmt jedoch nicht, da die Aussage gilt:
Die Daten (alle Einträge im Array cells sind in Cassandra unveränderlich in SSTables abgelegt.
Was hier geändert wurde, sind jedoch die Metainformationen.
Die Dateien zu dieser Tabelle bleiben jedoch auch nach dem Befehl nodetool compact in der Verzeichnisstruktur erhalten, jedoch wird eine neue Version geschrieben (me-2-* statt me-1-*). Es wird hier absichtlich nodetool compact durchgeführt, da ein nodetool flush nur die Einträge aus der Memtable in die SSTable überführt. Ein nodetool compact schreibt auch aktuelle Metainformationen in die SSTables.
root@a0617040d7df:/var/lib/cassandra/data/testkeyspace/testtablettl-115d708095bc11ed81e369687072559d# ls -lah
total 8.0K
drwxr-xr-x 1 cassandra cassandra 512 Jan 20 10:53 .
drwxr-xr-x 1 cassandra cassandra 512 Jan 16 16:37 ..
drwxr-xr-x 1 cassandra cassandra 512 Jan 16 16:37 backups
-rw-r--r-- 1 cassandra cassandra 51 Jan 20 10:53 me-2-big-CompressionInfo.db
-rw-r--r-- 1 cassandra cassandra 56 Jan 20 10:53 me-2-big-Data.db
-rw-r--r-- 1 cassandra cassandra 10 Jan 20 10:53 me-2-big-Digest.crc32
-rw-r--r-- 1 cassandra cassandra 16 Jan 20 10:53 me-2-big-Filter.db
-rw-r--r-- 1 cassandra cassandra 8 Jan 20 10:53 me-2-big-Index.db
-rw-r--r-- 1 cassandra cassandra 4.7K Jan 20 10:53 me-2-big-Statistics.db
-rw-r--r-- 1 cassandra cassandra 56 Jan 20 10:53 me-2-big-Summary.db
-rw-r--r-- 1 cassandra cassandra 92 Jan 20 10:53 me-2-big-TOC.txt
root@a0617040d7df:/var/lib/cassandra/data/testkeyspace/testtablettl-115d708095bc11ed81e369687072559d# /opt/cassandra/tools/bin/sstabledump me-2-big-Data.db
[
{
"partition" : {
"key" : [ "1" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 18,
"liveness_info" : { "tstamp" : "2023-01-20T10:22:38.764085Z", "ttl" : 120, "expires_at" : "2023-01-20T10:24:38Z", "expired" : true },
"cells" : [
{ "name" : "firstname", "deletion_info" : { "local_delete_time" : "2023-01-20T10:22:38Z" }
},
{ "name" : "lastname", "deletion_info" : { "local_delete_time" : "2023-01-20T10:22:38Z" }
}
]
}
]
}
]
Die neue Version rührt daher, dass nodetool compact die Daten aus der Verzeichnisstruktur entfernt, weil ja die Unveränderlichkeit der Daten in Cassandra gewahrt werden muss.
Jetzt könnte man natürlich fragen, wieso nicht die Datei-Einträge für diese Daten entfernt wurden?
Der Grund ist, dass wir hier immer noch über eine verteilte Datenbank sprechen.
Die hier abgelegten Daten sind mehrfach redundant im System abgelegt. Wenn also ein Datensatz aus Cassandra gelöscht wird, muss dafür Sorge getragen werden, dass auch alle Replikas des Datensatzes entfernt werden.
Das gleiche Prinzip trifft natürlich auch auf Datensätze zu, die mit TTL zur Löschung markiert sind.
Nachfolgend ein Beispiel.
Konsistenzwahrung im Cassandra-Cluster nach Datenlöschung
Die adressierte Problemstellung dieses Beitrags lässt sich am besten anhand eines Beispiels erklären.
- Eine Nachricht wurde mit Replication-Factor 3 in einen Cassandra-Cluster geschrieben.
- Der Datensatz wird entsprechend auf 3 Knoten geschrieben
- Ein Knoten, der diesen Datensatz enthält, fällt aus
- Das Quorum beim lesen / schreiben dieses Datensatzes ist nach wie vor gewahrt, da zwei Nodes von dreien die Nachricht zurückliefern können.
- Die Nachricht wird fachlich gelöscht, was bedeutet, dass dieser Datensatz im Cluster auf 2 von 3 Nodes als gelöscht markiert ist
- Ein nodetool compact wird ausgeführt, so dass die als gelöscht markierten Datensätze, physikalisch von der SSTable auf Disk gelöscht werden
- Jetzt fährt der ausgefallene 3. Knoten wieder hoch
Hieraus ergeben sich 2 Probleme.
- Der Last-Write-Wins-Algorithmus sorgt dafür, dass eine Nachricht die einmal im System (mit einem Zeitstempel) vorhanden ist als valide anerkennt
- Aus Sicht von Cassandra ist es eher valide einen Datensatz zurückzuliefern als keinen
Bei der Selektion auf diesen Datensatz würde aus fachlicher Sicht der bereits gelöschte Datensatz zurück geliefert werden, obwohl der ja bereits gelöscht wurde.
Diese Art von Datensätzen nennt man Zombi- oder Ghost-Datensatz.
Lösung für dieses Problem
gc_grace_seconds
„gc_grace_seconds“ ist ein Konfigurationsparameter in Cassandra-Datenbanken, der die Lebensdauer eines Datensatzes nach dem Löschen angibt. Nachdem ein Datensatz gelöscht wurde, bleibt er für die Dauer von „gc_grace_seconds“ verfügbar, bevor es endgültig gelöscht wird. Dies gibt Cassandra Zeit, um die Deletion auf allen Replikaten zu replizieren, bevor die Daten endgültig gelöscht werden.
Wenn ein Knoten, der Datensätze gelöscht hat, nach dem Ablauf von „gc_grace_seconds“ wieder in den Cassandra-Cluster aufgenommen wird, werden die gelöschten Datensätze auf diesem Knoten nicht automatisch wiederhergestellt.
Cassandra löscht Datensätze auf einem Knoten, wenn alle Replikate des Datensatzes aktualisiert wurden und „gc_grace_seconds“ abgelaufen ist. Wenn ein Knoten wieder in den Cluster aufgenommen wird, kann es zu einem Inkonsistenzproblem kommen, wenn der Knoten noch Datensätze hat, die auf anderen Knoten bereits gelöscht wurden.
Um solche Inkonsistenzen zu vermeiden, ist es wichtig, eine angemessene Überwachung des Cassandra-Clusters sowie regelmäßige Überprüfungen der Datenkonsistenz durchzuführen, um sicherzustellen, dass alle Knoten die gleichen Datensätze enthalten. In manchen Fällen kann es auch erforderlich sein, den Knoten, der wieder in den Cluster aufgenommen wurde, manuell zu bereinigen, um eine einheitliche Datenkonsistenz zu gewährleisten.
Es ist wichtig zu beachten, dass ein höherer Wert für „gc_grace_seconds“ die Wahrscheinlichkeit erhöht, dass aktualisierte Daten auf allen Replikaten repliziert werden, aber auch den benötigten Speicherplatz erhöht. Ein zu niedriger Wert kann dazu führen, dass alte Versionen der Daten noch vorhanden sind, wenn ein Knoten ausfällt. Daher sollte der Wert sorgfältig abgewogen werden, um eine gute Balance zwischen Verfügbarkeit und Speicherplatz zu erreichen.