Was wollen wir bauen?

Der Bauplan
Von der Idee zum fertigen Etwas, das funktioniert im Kleinen wie im Großen (meistens).
Also kurz zusammengekritzelt, was wollen wir machen?
- Grundsätzlich wollen wir Pi berechnen
- Die Berechnung erfolgt parallel auf mehreren Geräten
- Da wir nicht wissen wie viele Geräte Pi berechnen, soll das alles dynamisch erweitert werden können
- Änderungen an der Software sollen möglichst überall automatisch auf das entsprechende System übertragen werden.
- Die Software soll in Docker-Containern laufen
- Auf verschiedenen technologischen Plattformen
- Man soll eine Berechnung über eine fancy Oberfläche starten und entsprechend die Ergebnisse und Statistiken auf eben dieser Oberfläche betrachten
- Ergebnisse und Teilergebnisse sollen irgendwie für spätere Auswertungen gespeichert werden
- Wir brauchen irgend eine Komponente, die die Kommunikation für die Berechnungsaufträge und die Teilergebnisse übernimmt
- Wir verwenden C#
- Wir verwenden einen hybriden Betrieb aus Kubernetes mit ArgoCD und dem Betrieb als reine Docker-Anwendungen (Das wird dann ein eigener Artikel, versprochen).
- Wahrscheinlich brauchen wir noch mehr.
Wie immer sagen Bilder mehr als 1000 Worte, hier mal der grobe Bauplan, verifiziert von den Zwergen aus dem Teaser!
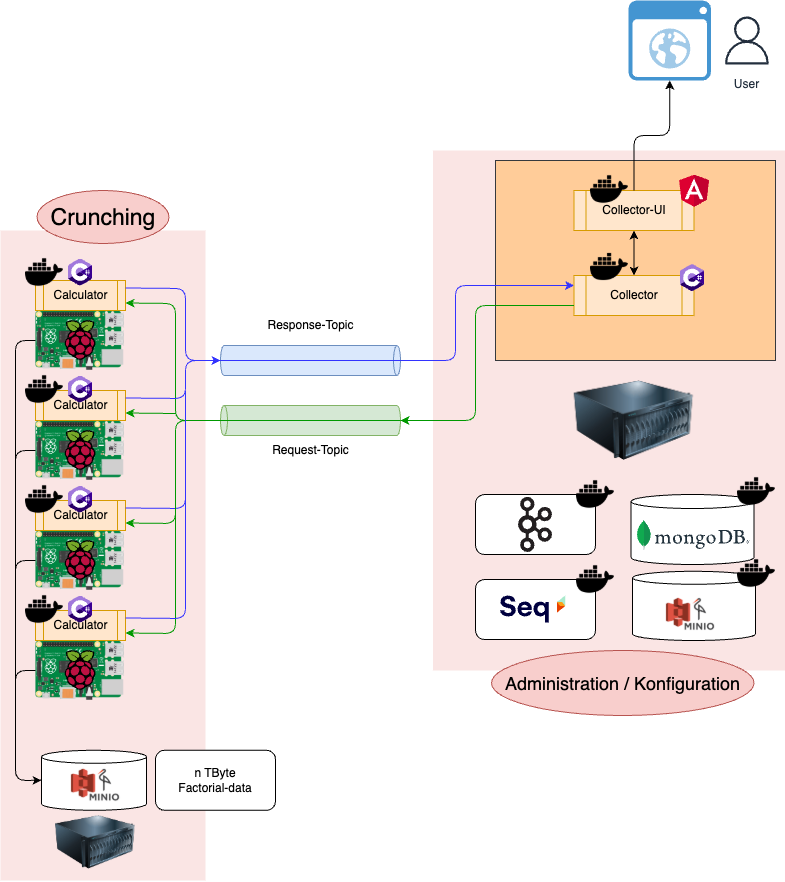
Eigentlich ganz einfach.
Der Benutzer darf über eine fancy UI (irgendwas mit Angular im Docker-Container) eine neue Berechnung von PI anlegen und starten. Den Status einer Berechnung bzw. das Ergebnis und ein paar Statistiken gibts auch noch dazu.
Der Collector ist ein Stück Software der zum einen ein paar RESTful-Api bereitstellt um das Frontend zu bedienen. Zum anderen sendet der die Calculation-Jobs über ein Request-Topics an die Worker-Nodes und die Ergebnisse sammelt das Ding aus einem Response-Topic wieder ein. Basis hierfür ist Kafka. Eigentlich würde eine Queue reichen, da ich nach der erfolgreichen Verarbeitung die Ergebnisse im Pub/Sub nicht mehr brauche, aber ein Kafka hatte ich gerade noch lokal gestartet.
Für alle die immer davon reden ein unfassbar aufgeblähtes Kafka hinzustellen! Firlefanz!
3-Node-System für Replication und Ausfallsicherheit. Mit relativ viel RAM und IO reichen für die meisten Sachen aus. Alles andere ist überkandidelter Quatsch und kostet nur Geld.
Die Ergebnisse werden in eine Mongo-DB geschrieben. Hier werden aber nur die Meta-Daten gespeichert. Die eigentlichen Daten sind Binaries, das tue ich Mongo-DB nicht an, diese werden in einem Minio-Storage abgelegt.
Logging und Tracing gehen via OTLP nach Seq.
Die Calculator sind eigentlich relativ einfache Dinger, die jeweils aus dem Request-Topic einen Iteration-Step herausnehmen, aus diesem jeweils genau eine Iteration der Chudnovsky-Formel berechnen und das Ergebnis in den Response-Topic schieben.
EZ
Eine Besonderheit ist hier der, tatsächlich hardware-basierte Minio Object-Store. Dieser dient als Cache und hält die Fakultäten für 1 – n. In einem späteren Kapitel dieses Beitrags gehe ich näher darauf ein.
Sind alle Iterationen berechnet, kann via UI noch das Gesamtergebnis berechnet werden. Dieses Gesamtergebnis ist dann eine Ganzzahl mit n Stellen und bildet den Dezimalteil von PI ab. Hier passen natürlich keine Standard-Datentypen mehr. Was wir hierfür verwenden, siehe hier!