Daten in verteilten Datenbanken lesen und schreiben
Wie ist eigentlich unser Testcluster aufgebaut?
Mit einem Cassandra-Cluster werden die unterschiedlichsten administrativen Tools installiert, mit dem sich solch ein Cluster verwalten lässt.
Das wichtigste, aller administrativen Tools, ist nodetool. Nodetool liefert zum einen sehr viele Informationen über den Cluster-Zustand, zum anderen auch die nötigen Befehle um den Cluster an seine Bedürfnisse anzupassem.
Um in unserem Falle das Tool zu erreichen ist es notwendig, sich in den Docker-Container zu verbinden und hier entsprechend das Tool zu nutzen (wir haben ja Cassandra in Docker-Containern laufen).
Selbstverständlich kann man sich nodetool und entsprechend Python auf die Host-Umgebung kopieren. Für diese Demonstrationszwecke ist es jedoch ausreichend die Befehle im Docker-Container auszuführen.
docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
867c5e34abde cassandra:3.11.14 "docker-entrypoint.s…" 11 minutes ago Up 11 minutes 7199/tcp, 0.0.0.0:17000->7000/tcp, 0.0.0.0:17001->7001/tcp, 0.0.0.0:19042->9042/tcp, 0.0.0.0:19160->9160/tcp docker-compose-cassandra2-1
86e5ee49db42 cassandra:3.11.14 "docker-entrypoint.s…" 11 minutes ago Up 11 minutes 7199/tcp, 0.0.0.0:27000->7000/tcp, 0.0.0.0:27001->7001/tcp, 0.0.0.0:29042->9042/tcp, 0.0.0.0:29160->9160/tcp docker-compose-cassandra3-1
332e9b2eee4d cassandra:3.11.14 "docker-entrypoint.s…" 11 minutes ago Up 11 minutes 0.0.0.0:7000-7001->7000-7001/tcp, 0.0.0.0:9042->9042/tcp, 0.0.0.0:9160->9160/tcp, 7199/tcp docker-compose-cassandra1-1
Mit docker ps -a` erhält man u.a. den Namen der gestarteten Docker-Container (im Beispiel oben, ganz nach rechts scrollen).
Einen Namen aussuchen und mit docker exec -ti docker-compose-cassandra1-1 bashdie Verbindung zur Konsole des Containers herstellen.
Dass das erfolgreich war, erkennt man an der geänderten Shell (in dem Falle bspw. root@332e9b2eee4d:/#).
Hoch lebe die Konsole, das Wichtigste zu nodetool
nodetool status
Den aktuellen Clusterstatus kann man am besten mit nodetool statusaufrufen.
Ganz interessant an dieser Stelle ist die Spalte Owns. Die sagt aktuell nichts vernünftiges aus. Warum? Naja, wir haben aktuell einen leeren Cassandra-Cluster mit nichts drin. Ein Keyspace mit einer Replication-Strategie bspw. würde hier Abhilfe schaffen. Aber dazu später.
root@332e9b2eee4d:/# nodetool status
Datacenter: tc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 10.30.10.4 66.32 KiB 8 69.9% 169209b8-83ba-49d0-a2e7-0a639d939fee rack1
UN 10.30.10.2 71.35 KiB 8 70.7% e9e5c51b-62ef-41ea-a637-d714a7de89a9 rack1
UN 10.30.10.3 71.48 KiB 8 59.3% dd53f441-bff6-4e4d-aa48-5e3db9c16ee6 rack1
nodetool ring
Detaillierte Informationen über den Zustand der Verteilung der Daten im Cluster und deren VNodes (virtuelle Token / Nodes) erhält man mit diesem Befehl. Je nach Anzahl der Nodes im Cluster und Anzahl der VNodes kann die Liste auch schon mal was länger werden. In unserem Falle ist das aber noch recht übersichtlich.
root@332e9b2eee4d:/# nodetool ring
Datacenter: tc1
==========
Address Rack Status State Load Owns Token
8759724549948524331
10.30.10.2 rack1 Up Normal 96.56 KiB 70.73% -8559473898326511762
10.30.10.3 rack1 Up Normal 71.48 KiB 59.33% -7581315443914370759
10.30.10.3 rack1 Up Normal 71.48 KiB 59.33% -6545580041922714934
10.30.10.4 rack1 Up Normal 66.32 KiB 69.93% -6314041728596461311
10.30.10.4 rack1 Up Normal 66.32 KiB 69.93% -5775727380262915329
10.30.10.4 rack1 Up Normal 66.32 KiB 69.93% -4227471048965011255
10.30.10.4 rack1 Up Normal 66.32 KiB 69.93% -4123866414696498839
10.30.10.2 rack1 Up Normal 96.56 KiB 70.73% -3459514687367540087
10.30.10.3 rack1 Up Normal 71.48 KiB 59.33% -3138927400709044823
10.30.10.2 rack1 Up Normal 96.56 KiB 70.73% -1387331114341155246
10.30.10.2 rack1 Up Normal 96.56 KiB 70.73% -924788451669375247
10.30.10.2 rack1 Up Normal 96.56 KiB 70.73% -658608299240828120
10.30.10.4 rack1 Up Normal 66.32 KiB 69.93% -179044577571798876
10.30.10.2 rack1 Up Normal 96.56 KiB 70.73% 126026321082294603
10.30.10.3 rack1 Up Normal 71.48 KiB 59.33% 1500058130403429444
10.30.10.3 rack1 Up Normal 71.48 KiB 59.33% 2512625010859810815
10.30.10.3 rack1 Up Normal 71.48 KiB 59.33% 2557321013244800540
10.30.10.2 rack1 Up Normal 96.56 KiB 70.73% 3879227540795169610
10.30.10.4 rack1 Up Normal 66.32 KiB 69.93% 4602476707380438857
10.30.10.3 rack1 Up Normal 71.48 KiB 59.33% 7264289972795196082
10.30.10.4 rack1 Up Normal 66.32 KiB 69.93% 7434482418213454743
10.30.10.4 rack1 Up Normal 66.32 KiB 69.93% 8062580910554045259
10.30.10.2 rack1 Up Normal 96.56 KiB 70.73% 8549928002780766666
10.30.10.3 rack1 Up Normal 71.48 KiB 59.33% 8759724549948524331
Warning: "nodetool ring" is used to output all the tokens of a node.
To view status related info of a node use "nodetool status" instead.
nodetool flush
Mit diesem Befehl veranlasst man Cassandra dazu alle Informationen die in den Memtables stehen, auf Disk zu schreiben. Für unsere Beispiele beim lesen, schreiben und löschen wird der noch öfter verwendet werden.
nodetool compact
Mit dem Befehl nodetool compact kann ein manueller Kompaktierungsvorgang (engl. Compaction) gestartet werden. Compaction bezieht sich auf das Zusammenfassen von mehreren kleinen Datenblöcken in den SSTables.
Der Vorteil einer Compaction ist, dass die Performance beim Lesen von Daten verbessert werden kann. Außerdem wird hierdurch Speicherplatz auf dem Datenträger freigegeben, da der Befehl gelöschte Datensätze entfernt (nach Ablauf von gc_grace_seconds).
Zu beachten ist, dass der Compaction-Vorgang ein sehr CPU- und speicherintensiver Vorgang ist, der die Performance des gesamten Cassandra-Clusters negativ beeinflussen kann. Deshalb sollten Compaction-Jobs möglichst in lastarme Zeiten gelegt werden.
Die Sache mit dem verteilten Lesen und Schreiben
Verteiltes lesen und schreiben in einer Cassandra bedeutet, das eine Nachricht mehrfach in diesem verteilten Speicher abgelegt werden sollte. Der Begriff dafür heißt Raplication. Mit dem Replication-Factor, einem Wert (Zahl von 1 – n) legt man fest, wie oft ein Datensatz in Cassandra abgelegt werden soll. Je höher der Replication-Factor umso größer die Ausfallsicherheit, zu Lasten des Speicherplatzes (und der Netz- bzw. IO-Performance).
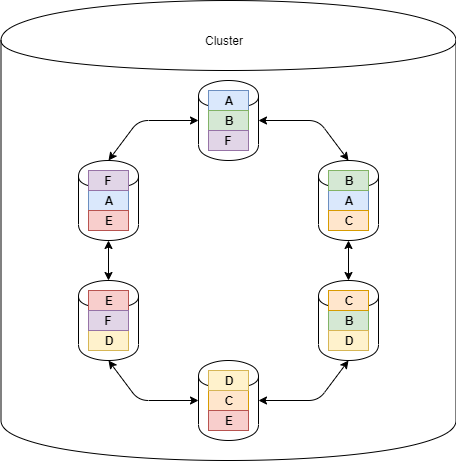
Beispiel
Die Nachrichten A bis F werden mit einem Replication-Factor 3 in eine Tabelle der Cassandra-Datenbank geschrieben.
Diese Nachrichten werden dann im Cassandra-Cluster verteilt. Die Verteilung im Cluster erfolgt aus der Berechnung eines Hash-Wertes, aus dem Schlüssel der Nachricht. Ein Knoten im Cluster bekommt beim initialen Start eine Sequenz von möglichen Hash-Werten zugewiesen (siehe oben).
Hierdurch ist es möglich eine Nachricht im Cassandra-Cluster zu speichern und auch wiederzufinden. Gleichzeitig werden die Nachrichten (bei einem Replication-Factor 3) auf 2 weitere Nodes im Cluster verteilt.
Vorteile
Durch diese Art der Speicherung und der Verteilung der Daten ist garantiert, dass selbst bei Ausfall von 2 Knoten im Cluster, die Nachricht immer noch einmal vorliegt und gelesen werden kann. Sollte eine höhere Ausfallsicherheit erreicht werden müssen, wird einfach der Replication-Factor entsprechend erhöht was zu Lasten des Gesamtspeicherplatzes des Clusters geht.
Durch die Hinzunahme weiterer Knoten in den Cluster, ist es möglich die Performance und den Speicherplatz nahezu unendlich zu erhöhen.
Nachteile
Der größte Nachteil bei dieser Art der Datenspeicherung, nennt sich Eventual Consistency.
Werden Daten bspw. mit einem Replication-Factor 3 geschrieben, benötigt das Gesamtsystem eine gewisse Zeit um die Nachrichten im Verbund zu replizieren. Während dieser Zeit ist die Nachricht, aus Sicht des Gesamtsystems nicht konsistent vorhanden (bspw. einmal geschrieben, zwei mal noch nicht).
Alle verteilten Datenspeicher haben dieses „Problem“. Es wird dadurch verstärkt, wenn Nachrichten über Rechenzentrumsgrenzen hinweg repliziert werden müssen.
Daher leitet sich auch die Wortschöpfung „Eventual Consistency“ ab. Es kann nicht garantiert werden, das zu einem Zeitpunkt X für eine Nachricht die Konsistenz im verteilten Datenbanksystem erreicht ist. Die Konsistenz wird eventuell erreicht werden (wenn bspw. dieser Datensatz genügend lange nicht verändert wurde).
Ausweg aus dem Dilemma
Um dem Eventual Consistency Problem entgegen zu wirken, wird für verteilte Datenbank-Systeme die Quorum basierte Replikation angewandt. Ein Quorum (lat. Mehrzahl) ist in einem verteilten Datenbanksystem dann erreicht, wenn eine Nachricht mehrheitlich von Cassandra geschrieben oder mehrheitlich von Cassandra gelesen werden kann.
Um sicherzustellen, dass Daten mit einer möglichst hohen Konsistenz (im Sinne der Verfügbarkeit) gelesen werden, sollte folgende Regel beachtet werden.
CL.READ = Konsistenzlevel (CL) der für Lesevorgänge verwendet wird. Entspricht der Anzahl der Cassandra-Nodes, die den Lesevorgang bestätigen müssen, damit dieser Vorgang aus Sicht von Cassandra erfolgreich ist.
CL.WRITE = Konsistenzlevel (CL) der für Schreibvorgänge angewandt wird. Entspricht der Anzahl der Cassandra-Nodes, die den Schreibvorgang bestätigen müssen, damit dieser Vorgang aus Sicht von Cassandra erfolgreich ist.
RF = Replication-Factor
Eine hohe Konsistenz ist erreicht wenn
CL.READ + CL.WRITE > RF`
ist. Wenn CL.READ + CL.WRITE > RF ist, ist sichergestellt, dass man von mindestens einem Knoten Daten lesen kann auf dem dieser Datensatz geschrieben wurde.
Beispiel für einen häufigen Anwendungsfall:
RF = 3
Quorum von 3 ist 2.
CL.READ = 2
CL.WRITE= 2
CL.READ + CL.WRITE > RF --> 4 > 3
Mit dieser Konfiuration erreicht man eine hohe Verfügbarkeit, da es keinen Single Point of Failure gibt. Man kann 2 Knoten verlieren, da sichergestellt ist, dass jeder Lesevorgang die geschriebenen Daten auf mindestens einen Knoten abrufen kann. Durch Anwendung des Last-Write-Wins (LWW)-Algorithmus wird gewährleistet das der zuletzt geschriebene Datensatz als Ergebnis zurückgegeben wird.
Dieser Last-Write-Wins Algorithmus wird jedoch an anderer Stelle noch zum Problem.
Konsistenzlevel beim Lesen und Schreiben aus fachlicher Sicht
Aus fachlicher Sicht kann man Daten mit unterschiedlichen Konsistenzlevel lesen, schreiben und löschen.
Beispiele
QUORUM (LOCAL_QUORUM wenn das Quorum im aktuellen Datacenter erfüllt sein muss).
Ich möchte einen Datensatz mit QUORUM lesen. Der Keyspace ist mit Replication Factor 3 angelegt.
Ein Node, der eine Replik der angefragten Nachricht hält ist ausgefallen.
Der Lesevorgang ist erfüllt, da 2 von 3 Nodes die Antwort zurückliefern.
Ich möchte einen Datensatz mit QUORUM schreiben. Der Keyspace ist mit Replication Factor 3 angelegt.
Zwei Nodes auf denen die Replik geschrieben werden soll sind ausgefallen.
Der Schreibvorgang wird mit einem Fehler an den Client zurückgemeldet, da dass festgelegte Quorum von 2 beim Schreiben nicht erfüllt werden kann.
Weitere Konsistenzlevel sind beispielsweise:
- ALL (stärkstes Konsistenzlevel), alle Nodes müssen Schreib-, Lese- oder Löschvorgänge bestätigen.
- ONE (lesend) oder ANY (schreibend), wenigstens ein Node muss eine Antwort liefern, den Write bestätigen.
Weitere Informationen zu den unterschiedlichen Konsistenzlevel und deren Verwendung kann man u.a. hier finden.
https://doc.dovecot.org/settings/plugin/sql-cassandra/#cassandra-consistency
Lesen und Schreiben von Daten in Cassandra
Schauen wir uns das Lesen und viel interessanter das Schreiben von Informationen in Cassandra an.
In Cassandra ist mit cqlsh (Cassandra Query Language Shell) ein Tool enthalten, mit der in der Konsole Daten gelesen / manipuliert / gelöscht werden können.
Ein einfacher Aufruf von cqlsh reicht jedoch nicht aus, da wir den Cassandra-Docker-Container mit einer IP-Adresse gestartet und diese IP-Adresse an Cassandra gebunden haben.
Also verwenden wir
root@332e9b2eee4d:~# cqlsh 10.30.10.2
Connected to TestCluster at 10.30.10.2:9042.
[cqlsh 5.0.1 | Cassandra 3.11.14 | CQL spec 3.4.4 | Native protocol v4]
Use HELP for help.
cqlsh>
Und siehe da, wir sind verbunden mit einem Cassandra Node des TestCluster.
Zuerst mal legen wir einen Keyspace in Cassandra an. Ein Keyspace ist grob vergleichbar mit einer Datenbank im RDBMS. Für mich ist ein Keyspace eine Klammer um eine fachliche Domäne. In einem Keyspace definieren wir außerdem mit welchen Replication-Factor die Daten im Cluster verteilt werden und welche Replication-Strategy angewandt wird.
Für uns reicht als Replication-Strategy SimpleStrategy mit einem Replication-Factor 3.
cqlsh> CREATE KEYSPACE testkeyspace WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};
Schauen wir uns mal an, was das mit dem Cassandra-Cluster gemacht hat.
Ein nodetool status ergibt jetzt folgendes Bild.
nodetool status
Datacenter: tc1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 10.30.10.4 106.71 KiB 8 100.0% 169209b8-83ba-49d0-a2e7-0a639d939fee rack1
UN 10.30.10.2 130.04 KiB 8 100.0% e9e5c51b-62ef-41ea-a637-d714a7de89a9 rack1
UN 10.30.10.3 117.15 KiB 8 100.0% dd53f441-bff6-4e4d-aa48-5e3db9c16ee6 rack1
Man beachte die Owns-Spalte. Diese ist, im Gegensatz zum ersten nodetool status Aufruf für alle 3 Nodes auf 100.0% angewachsen.
Warum? Na ganz einfach. Bei 3 Nodes und Replication Factor 3 werden alle Datensätze auf allen Nodes verteilt. Das ist relativ einfache Mathematik vorauszusehen, das jeder Node 100% der Daten hält.
Und weiter geht´s. Wir legen eine Tabelle an. Diese Tabelle wird ein Id-Feld (Zahl) und 2 Textfelder enthalten.
Das Id-Feld wird der Schlüssel.
Ganz einfach.
cqlsh> USE testkeyspace ;
cqlsh:testkeyspace> CREATE TABLE testtable (id int PRIMARY KEY, firstname text, lastname text);
Zuerst wechseln wir in den gerade neu angelegten Keyspace, dann legen wir darin die Tabelle an.
Fertig!
Ein
cqlsh:testkeyspace> SELECT * from testtable ;
id | firstname | lastname
----+-----------+----------
(0 rows)
liefert erwartungsgemäß kein Ergebnis zurück.
Jetzt geht´s ans Eingemachte.
In Cassandra existiert ein weiteres, administratives Tool mit dem man auf Dateiebene Daten auslesen kann. Im folgenden werden wir also mittels cqlsh Datensätze schreiben und mittels sstabledump anschauen wie Cassandra die Daten tatsächlich ablegt. Gleichzeitig werfen wir noch einen Blick auf das Dateisystem. Dadurch erhält man einen ganz guten Einblick, dass das was ich im vorigen Beitrag geschrieben habe auch irgendwie zu stimmen scheint.
Für jede Tabelle legt Cassandra im Dateisystem ein Verzeichnis an. Die Dateien sind in meinem Fall in /var/lib/cassandra/data/testkeyspace/testtable-[32byte string]/ abgelegt.
root@332e9b2eee4d:/var/lib/cassandra/data/testkeyspace/testtable-7109d27091e911ed967e69687072559d# ls -lah
total 0
drwxr-xr-x 1 cassandra cassandra 512 Jan 11 19:52 .
drwxr-xr-x 1 cassandra cassandra 512 Jan 11 19:52 ..
drwxr-xr-x 1 cassandra cassandra 512 Jan 11 19:52 backups
Ein leeres Verzeichnis, alles andere wäre auch schrecklich, wir haben ja noch gar keine Daten eingefügt!
Also werden wir mal einen Datensatz in die Tabelle einfügen.
cqlsh:testkeyspace> INSERT INTO testtable (id, firstname, lastname) VALUES ( 1, 'hans', 'meier');
Man möge mir die Einfallslosigkeit mit dem Namen verzeihen. Aber nun ja.
Jetzt sollte auch ein auslesen funktionieren.
cqlsh:testkeyspace> SELECT * from testtable ;
id | firstname | lastname
----+-----------+----------
1 | hans | meier
(1 rows)
Wunderbar!
Und was hat das jetzt mit unserem Dateisystem gemacht?
root@332e9b2eee4d:/var/lib/cassandra/data/testkeyspace/testtable-7109d27091e911ed967e69687072559d# ls -lah
total 0
drwxr-xr-x 1 cassandra cassandra 512 Jan 11 19:52 .
drwxr-xr-x 1 cassandra cassandra 512 Jan 11 19:52 ..
drwxr-xr-x 1 cassandra cassandra 512 Jan 11 19:52 backups
Scheint kaputt zu sein?
Nein, ganz im Gegenteil! Wir haben im vorigen Beitrag gelernt, dass Datensätze zuerst in mutable Memtable geschrieben werden, bevor sie, wenn die Memtable voll ist, in eine immutable SSTable überführt werden.
Beweis für die Mutable Memtable? Wir aktualisieren den Vornamen und rufen den Datensatz ab. Siehe da, der Vorname ist geändert.
cqlsh:testkeyspace> UPDATE testtable set firstname = 'paule' where id = 1;
cqlsh:testkeyspace> SELECT * from testtable ;
id | firstname | lastname
----+-----------+----------
1 | paule | meier
(1 rows)
Und im Dateisystem?
root@332e9b2eee4d:/var/lib/cassandra/data/testkeyspace/testtable-7109d27091e911ed967e69687072559d# ls -lah
total 0
drwxr-xr-x 1 cassandra cassandra 512 Jan 11 19:52 .
drwxr-xr-x 1 cassandra cassandra 512 Jan 11 19:52 ..
drwxr-xr-x 1 cassandra cassandra 512 Jan 11 19:52 backups
Da sich sehr wenig Daten in der Memtable befinden, werden die Daten vielleicht für eine sehr lange Zeit nicht als SSTable auf Disk geschrieben. Sie sind aber trotzdem 3 fach repliziert vorhanden, da sie im Commit-Log der Cassandra-Node geschrieben werden und durch das replizieren der Memtable die Daten auf die Commit-Logs der anderen Nodes kopiert werden.
Wir rufen also ein nodetool flush auf und schauen uns das mal im Dateisystem an. Hierzu gibt es keine Ausgabe die dargestellt werden kann.
Allerdings sieht man jetzt im Dateisystem.
root@332e9b2eee4d:/var/lib/cassandra/data/testkeyspace/testtable-7109d27091e911ed967e69687072559d# ls -lah
total 8.0K
drwxr-xr-x 1 cassandra cassandra 512 Jan 11 20:13 .
drwxr-xr-x 1 cassandra cassandra 512 Jan 11 19:52 ..
drwxr-xr-x 1 cassandra cassandra 512 Jan 11 19:52 backups
-rw-r--r-- 1 cassandra cassandra 43 Jan 11 20:13 me-1-big-CompressionInfo.db
-rw-r--r-- 1 cassandra cassandra 49 Jan 11 20:13 me-1-big-Data.db
-rw-r--r-- 1 cassandra cassandra 10 Jan 11 20:13 me-1-big-Digest.crc32
-rw-r--r-- 1 cassandra cassandra 16 Jan 11 20:13 me-1-big-Filter.db
-rw-r--r-- 1 cassandra cassandra 8 Jan 11 20:13 me-1-big-Index.db
-rw-r--r-- 1 cassandra cassandra 4.7K Jan 11 20:13 me-1-big-Statistics.db
-rw-r--r-- 1 cassandra cassandra 56 Jan 11 20:13 me-1-big-Summary.db
-rw-r--r-- 1 cassandra cassandra 92 Jan 11 20:13 me-1-big-TOC.txt
Die Daten sind von der Memtable in die SSTable (string sorted table) auf Disk geschrieben. Fein!
Allerdings in irgendeinem Binärformat. Jetzt kommt sstabledump ins Spiel und schauen uns das mal an. Folgender Befehl lädt das Tool und interpretiert die Daten aus der Tabelle um sie strukturiert darzustellen.
root@332e9b2eee4d:/var/lib/cassandra/data/testkeyspace/testtable-7109d27091e911ed967e69687072559d# /opt/cassandra/tools/bin/sstabledump me-1-big-Data.db
[
{
"partition" : {
"key" : [ "1" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 18,
"liveness_info" : { "tstamp" : "2023-01-11T20:03:37.791839Z" },
"cells" : [
{ "name" : "firstname", "value" : "paule", "tstamp" : "2023-01-11T20:08:18.543316Z" },
{ "name" : "lastname", "value" : "meier" }
]
}
]
}
]
Haken dran! Wir sehen die Werte im Datensatz. Wir sehen sogar auch, dass der Vorname offensichtlich bereits geändert in die SSTable eingefügt wurde, da dieser bereits ein Attribut tstamp hat.
Wir ändern jetzt nochmal den Vornamen.
cqlsh:testkeyspace> UPDATE testtable set firstname = 'siegfried' where id = 1;
cqlsh:testkeyspace> SELECT * from testtable ;
id | firstname | lastname
----+-----------+----------
1 | siegfried | meier
(1 rows)
Fein, auch das hat funktioniert. Und technisch? Ich führe jetzt mal das nodetool flush direkt aus, weil wir wissen, dass die Daten des Updates vorerst nicht in der SSTable geschrieben sind sondern in der Memtable vorliegen.
Nach dem ausführen von nodetool flush sehen wir folgendes im Dateisystem.
root@332e9b2eee4d:/var/lib/cassandra/data/testkeyspace/testtable-7109d27091e911ed967e69687072559d# ls -lah
total 16K
drwxr-xr-x 1 cassandra cassandra 512 Jan 11 20:36 .
drwxr-xr-x 1 cassandra cassandra 512 Jan 11 19:52 ..
drwxr-xr-x 1 cassandra cassandra 512 Jan 11 19:52 backups
-rw-r--r-- 1 cassandra cassandra 43 Jan 11 20:13 me-1-big-CompressionInfo.db
-rw-r--r-- 1 cassandra cassandra 49 Jan 11 20:13 me-1-big-Data.db
-rw-r--r-- 1 cassandra cassandra 10 Jan 11 20:13 me-1-big-Digest.crc32
-rw-r--r-- 1 cassandra cassandra 16 Jan 11 20:13 me-1-big-Filter.db
-rw-r--r-- 1 cassandra cassandra 8 Jan 11 20:13 me-1-big-Index.db
-rw-r--r-- 1 cassandra cassandra 4.7K Jan 11 20:13 me-1-big-Statistics.db
-rw-r--r-- 1 cassandra cassandra 56 Jan 11 20:13 me-1-big-Summary.db
-rw-r--r-- 1 cassandra cassandra 92 Jan 11 20:13 me-1-big-TOC.txt
-rw-r--r-- 1 cassandra cassandra 43 Jan 11 20:36 me-2-big-CompressionInfo.db
-rw-r--r-- 1 cassandra cassandra 41 Jan 11 20:36 me-2-big-Data.db
-rw-r--r-- 1 cassandra cassandra 10 Jan 11 20:36 me-2-big-Digest.crc32
-rw-r--r-- 1 cassandra cassandra 16 Jan 11 20:36 me-2-big-Filter.db
-rw-r--r-- 1 cassandra cassandra 8 Jan 11 20:36 me-2-big-Index.db
-rw-r--r-- 1 cassandra cassandra 4.6K Jan 11 20:36 me-2-big-Statistics.db
-rw-r--r-- 1 cassandra cassandra 56 Jan 11 20:36 me-2-big-Summary.db
-rw-r--r-- 1 cassandra cassandra 92 Jan 11 20:36 me-2-big-TOC.txt
Was ist das jetzt? Der Zeitstempel der Dateien mit me-1- am Anfang beweist (letzte Änderung 20:13) das wir für das Update eine neue Reihe an Dateien angelegt haben mit einem neuen Zeitstempel (me-2- um 20:36). Damit ist bewiesen, dass einmal geschriebene SSTable immutable also unveränderlich im Dateisystem abgelegt sind.
Der Inhalt von me-1- ist bekannt.
Und der Inhalt vom me-2-?
root@332e9b2eee4d:/var/lib/cassandra/data/testkeyspace/testtable-7109d27091e911ed967e69687072559d# /opt/cassandra/tools/bin/sstabledump me-2-big-Data.db
[
{
"partition" : {
"key" : [ "1" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 18,
"cells" : [
{ "name" : "firstname", "value" : "siegfried", "tstamp" : "2023-01-11T20:34:09.483379Z" }
]
}
]
}
]
Damit ist bewiesen, dass alles was in den schlauen Büchern so drin steht, auch tatsächlich so passiert.
Somit wird aber auch klar, weshalb viele Änderungen an bestehenden Datensätzen in Cassandra zwangsläufig zu einem Performance-Problem werden können, da das selektieren eines einzigen Datensatzes sehr viele Dateien lesen und die Inhalte zusammenführen muss.
Noch kurz das aufräumen erklärt
Mittels nodetool compact haben wir die Möglichkeit alle Versionen einer SSTable zusammenzuführen zu einer einzigen neuen Version. Dafür wird aber (Stichwort immutable) aus allen „alten“ Versionen eine neue gemacht. In unserem Fall haben die Dateien danach den Prefix me-3-. Der Einfachheit halber wird die Ausgabe mal in einem Codeblock zusammengefasst.
root@332e9b2eee4d:/var/lib/cassandra/data/testkeyspace/testtable-7109d27091e911ed967e69687072559d# nodetool compact
root@332e9b2eee4d:/var/lib/cassandra/data/testkeyspace/testtable-7109d27091e911ed967e69687072559d# ls -lah
total 8.0K
drwxr-xr-x 1 cassandra cassandra 512 Jan 11 20:51 .
drwxr-xr-x 1 cassandra cassandra 512 Jan 11 19:52 ..
drwxr-xr-x 1 cassandra cassandra 512 Jan 11 19:52 backups
-rw-r--r-- 1 cassandra cassandra 51 Jan 11 20:51 me-3-big-CompressionInfo.db
-rw-r--r-- 1 cassandra cassandra 62 Jan 11 20:51 me-3-big-Data.db
-rw-r--r-- 1 cassandra cassandra 10 Jan 11 20:51 me-3-big-Digest.crc32
-rw-r--r-- 1 cassandra cassandra 16 Jan 11 20:51 me-3-big-Filter.db
-rw-r--r-- 1 cassandra cassandra 8 Jan 11 20:51 me-3-big-Index.db
-rw-r--r-- 1 cassandra cassandra 4.7K Jan 11 20:51 me-3-big-Statistics.db
-rw-r--r-- 1 cassandra cassandra 56 Jan 11 20:51 me-3-big-Summary.db
-rw-r--r-- 1 cassandra cassandra 92 Jan 11 20:51 me-3-big-TOC.txt
root@332e9b2eee4d:/var/lib/cassandra/data/testkeyspace/testtable-7109d27091e911ed967e69687072559d# /opt/cassandra/tools/bin/sstabledump me-3-big-Data.db
[
{
"partition" : {
"key" : [ "1" ],
"position" : 0
},
"rows" : [
{
"type" : "row",
"position" : 18,
"liveness_info" : { "tstamp" : "2023-01-11T20:03:37.791839Z" },
"cells" : [
{ "name" : "firstname", "value" : "siegfried", "tstamp" : "2023-01-11T20:34:09.483379Z" },
{ "name" : "lastname", "value" : "meier" }
]
}
]
}
]
Fazit
Auf diese Art und Weise werden in Cassandra Daten gespeichert. Das was in den obigen Beispielen beschrieben wurde, geschieht in der Realität tatsächlich mit sehr viel größeren Datenmengen und Operationen. Hier wird auch verständlicher, dass die Auswahl von Cassandra als Datenspeichersystem eher nach einem stabilen Datenbestand strebt bzw. häufige Änderungen oder Löschungen eher als Antipattern betrachtet werden können.