Das Mysterium "Verteilte Datenbanken" verstehen
Was schreibt denn Wikipedia so?
Ein verteiltes Datenbankmanagementsystem ist ein Datenbankmanagementsystem (DBMS), das ein gewisses Maß an Autonomie, Heterogenität und Verteilung (Mehrrechner-Datenbanksystem) aufweist. Je nach Ausprägung dieser drei Kriterien in einem lassen sich verschiedene verteilte DBMS unterscheiden.
Beispiele für verteilte DBMS sind Master-Slave-Systeme, Client-Server-Systeme (gering verteilt) und Peer-to-Peer Systeme (stark verteilt).
Quelle: https://de.wikipedia.org/wiki/Verteiltes_Datenbankmanagementsystem
Dieser Artikel beschäftigt sich mit dem verteilten Datenbanksystem Apache / Datastax Cassandra, dass innerhalb der verteilten Datenbank-Systeme zu den stark verteilten Systemen (peer-to-peer) gehört. Im folgenden wird ausschließlich der Terminus Cassandra verwendet, die Funktionsweise ist bei beiden Produkten die Selbe.
Eine Gemeinsamkeit aller verteilten Datenbank-Typen ist, dass sie dem CAP-Theorem folgen. Dieses sagt aus, dass es in einem verteilten System unmöglich ist, gleichzeitig die Eigenschaften Consistency (Konsistenz), Availability (Verfügbarkeit) und Partition Tolerance (Ausfallsicherheit) zu garantieren.
Und was bedeutet das?
Eine verteilte Datenbank kann, laut den CAP-Theorem, maximal 2 der oben genannten Eigenschaften gleichzeitig erfüllen, jedoch nie alle 3.
Beispiele für Systeme die diesem Grundsatz folgen.
AP – DNS (Domain Name System) oder verteilte Datenbanken (bspw. Cassandra). Eine sehr hohe Verfügbarkeit und eine hohe Toleranz gegenüber dem Ausfall einzelner Knoten wird hier angestrebt. Dies geht eindeutig zu Lasten der Konsistenz, was bei DNS bspw. durch Inkonsistenzen von >24 Stunden bei der Verteilung der Daten in Kauf genommen wird.
CA – RDBMS (Oracle, PostgreSQL) – Wahrung der Konsistenz und Verfügbarkeit, wenn das RDBMS (im Rahmen seiner Möglichkeiten) als verteiltes System ausgelegt wird. Hier sind, gerade für die Wahrung der Konsistenz Abstriche bei der Entfernung der miteinander verbundenen verteilten RDBMS-Systeme zu machen.
CP – Verteilte Anwendungen für Finanztransaktionen – Konsistenz wird gewahrt bei gleichzeitig hoher Partitionstoleranz..

Dieser Beitrag beschäftigt sich mit Systemen aus der Kategorie AP. Ein Vertreter dieser Kategorie ist das Datenbank-System Cassandra. Wie oben erwähnt, gelten die folgenden Eigenschaften für verteilte Systeme dieser Art:
- Die Availability – Verfügbarkeit – bezieht sich immer auf das Gesamtsystem.
- Partition Tolerance – Partitionstoleranz – bezieht sich darauf, dass in diesem verteilten System einer oder mehrere Knoten ausfallen können, ohne die Funktionsweise des Gesamtsystems zu beeinträchtigen.
Weitere Eigenschaften von Cassandra als verteiltes Datenbank-System sind:
- Definierbares Level an Konsistenz der Daten (Anzahl der Replicas)
- Jeder Knoten in einem Cassandra-Cluster hat die gleiche Funktion, es gibt keine Master-Knoten. Es gibt Koordinatoren, was wiederum jeder Knoten im Cluster übernehmen kann.
- Hoch skalierbar, nahezu unendlich horizontale Verteilung von Knoten möglich
- Die hohe Skalierbarkeit bezieht sich ausdrücklich auf den Multi-Rechenzentrums-Betrieb
- Keine Backups notwendig, da die konfigurierbare Skalierbarkeit diese überflüssig macht
Es soll aber auch ganz klar auf die Nachteile dieses Systems eingegangen werden. Diese sind u.a.
- Keine Selektierbarkeit im Sinne eines RDBMS
- Keine Indices
- Rudimentäre Trigger
- Keine Stored-Procedures oder User Defined Functions
- Keine Konsistenz
- Löschen von großen Datenmengen ist ein Antipattern
- Ständiges Verändern von Datensätzen ist ein Antipattern
Gerade der erste Punkt wird dann problematisch, wenn viele Selektionsmöglichkeiten der Daten geschaffen werden sollen. Hier muss man mit Meta-Tabellen Abhilfe schaffen, die einen hohen Migrationsaufwand erfordern und je nach Datenbestand eine lange Zeit in Anspruch nehmen können. Die Auswahl eines geeigneten Suchindex-Produktes ist hier in vielen Fällen die bessere Alternative.
Und wie kommen die Daten in die Datenbank?
Beim initialen Start eines Cassandra-Clusters werden auf die Nodes (einzelner Rechner) des Clusters die Werte von Java-Long (-9,223,372,036,854,775,808 bis +9,223,372,036,854,775,807) ungleichmäßig verteilt. Diese Zahl 3.40282366920938463463374607431768211456 × 10^38 ist die maximale Anzahl von Datensätzen, die in Cassandra geschrieben werden können.
Dieser Wert wird auch Token genannt. In einem Cluster sind alle Nodes mit verteilten Werten zu einem Token-Ring aufgespannt.
Wieso ungleichmäßig Verteilung?
Ein Cassandra-Cluster kann beliebig erweitert werden. Ohne manuellen Eingriff werden die Anteile die jeder Node vom Long-Value erhält immer willkürlich von einem anderen Node entnommen. Danach findet eine Reorganisation des Clusters statt.
Auch die Entnahme von Nodes ist so möglich.
Die Daten werden von einem Node entgegen genommen. Aus dem Schlüssel (Key) des Datensatz wird ein Hash-Wert ermittelt. Mit diesem Hashwert (Java Long-Value) wird der Node ermittelt, auf dem der Datensatz geschrieben wird.
Es gibt durchaus Szenarien, bei denen die Ungleichverteilung der Token pro Node ungünstig ist, bspw. wenn große Datensätze geschrieben werden und damit, speicherplatztechnisch, ein Node viel mehr Daten hält als andere Nodes.
Für dieses Szenario gibt es ein administratives Tool innerhalb der Clusteradministration, mit denen die Token im Cluster exakt gleichverteilt werden können.
Und welche Nodes werden als Replica-Nodes ermittelt?
Das hängt von von der sogenannten Replication-Strategy ab.
Am einfachsten ist die SimpleStrategy. Hier wird, ausgehend vom Node, auf dem die initiale Nachricht geschrieben wird (die zum Token passt) die jeweils vorige und nächste Node für die Replica verwendet.
Da alle Nodes in einem Cluster gleichberechtigt sind, ist die Ausfallwahrscheinlichkeit für den nächsten bzw. vorigen Node genauso hoch wie für einen Node, der sich weiter entfernt im Ring befindet.
Bei der NetworkTopologyStrategy wird zusätzlich noch das Datacenter berücksichtigt. Jeder Cassandra-Cluster kann über beliebig viele Datacenter aufgespannt werden. Wird diese Strategie gewählt, werden die Datensätze über unterschiedliche Datacenter verteilt.
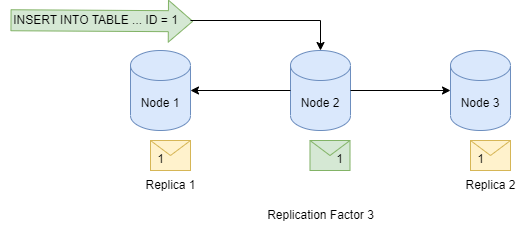
Datenverarbeitung in Cassandra
Entgegennahme der Daten und Verteilung
Wenn ein Datensatz in Cassandra geschrieben wird, passiert intern folgendes:
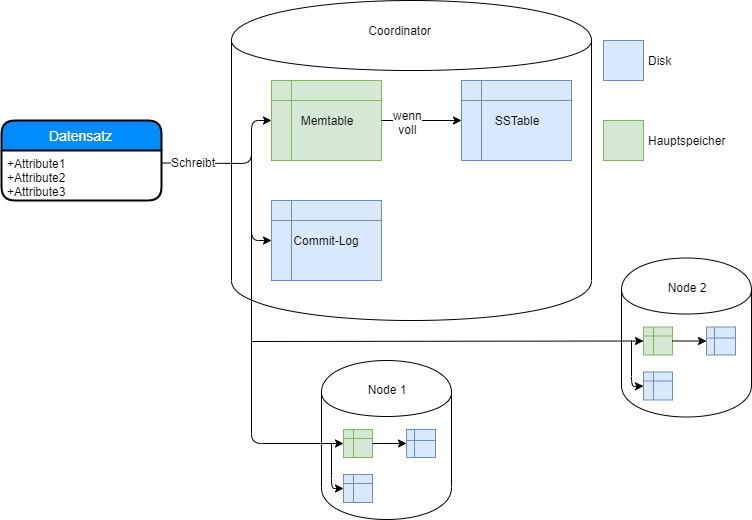
Die Daten werden vom Koordinator-Node entgegen genommen und in die Memtable geschrieben. Die Memtable ist ein Key-Value-Store im Hauptspeicher des Nodes. Die Memtable hält die Daten vor bis sie voll ist und dann werden die Daten von der Memtable auf Disk transferiert.
Aber warum ist das so?
Im nächsten Abschnitt erfahren wir, dass Daten, sobald sie auf Disk gespeichert sind, unveränderlich (immutable) sind. Eine Memtable ist also eine Optimierung der IO-Performance. Denn Daten in der Memtable sind mutable (also veränderlich). Änderungen an einem Datensatz in der Memtable werden direkt am Datensatz durchgeführt.
Das Commit-Log ist eine (kleines) Backup der Memtable. Sollte eine Node kaputt gehen, besteht die Chance, dass ein Teil der Daten aus der Memtable im Commit-Log gespeichert sind.
Die Daten werden, sobald sie in die Memtable geschrieben werden, auf die anderen Nodes (je nach Replication-Factor) verteilt. Auf den anderen Nodes erfolgt der gleiche Prozess.
Speicherung der Daten im Dateisystem
Werden Informationen in Cassandra geschrieben, geschieht das mittels protokollstrukturierter Zusammenführung (LSM-Tree1). Elementar für einen LSM-Tree ist, das jede Veränderung an einem Datensatz in einer unveränderlichen Datei (immutable Dataset) gespeichert wird. Wenn diese Dateien immutable sind, bedeutet das auch, das eine Änderung an einem Datensatz immer nur durch eine neue Version der Änderung erfolgen kann.
Im Gegensatz zu Cassandra, verwenden herkömmliche RDBMS als Datenspeicherung meistens einen B-Tree2.

Die Fragmente der „alten“ Versionen zu Nachrichten werden in diesem Zusammenhang als Tombstone bezeichnet.

Aus dem obigen Beispiel kann man die ersten Einträge aus dem Stack auch als Tombstone darstellen. Dies ist jedoch nur eine sehr einfache Darstellung. In den späteren Beispielen werden wir sehen, dass ein Tombstone spaltenbasiert erzeugt wird. Soll heißen. Wenn eine Tabelle mit Spalte A, B, C geschrieben und danach Spalte B verändert wird, entsteht ein Tombstone ausschließlich für den Wert der Spalte B. Spalte A und C bleiben gültig.
Tombstones
Das Wort Tombstone (engl. für Grabstein) in der Welt der verteilten Daten, lege ich mal als Erinnerungsmerkmal aus.
Quasi: Hier liegt eine alte Version eines Datensatzes.
Und wofür brauche ich das?
Durch die Unveränderlichkeit der Dateien auf den Nodes ist gewährleistet, dass der physikalische Datenstand im gesamten Cluster über alle Nachrichten möglichst konsistent ist. Wenn eine Nachricht verändert wird, wird über den Replication-Factor eine neue Version des Nachrichtenteils auf den Cluster repliziert und dort abgelegt. Das ist weitaus performanter als jedes mal in den Nodes eine Datei zu öffnen und diese zu verändern.

Irgendwann muss man ja mal aufräumen (Compaction)
Durch Veränderungen an Datensätzen (UPDATES und DELETES) werden immer neue Versionen von Nachrichten als unveränderliche Dateien in das Dateisystem von verteilten Datenbanken geschrieben. Dies hat zur Folge, dass das Lesen von Datensätzen alle Fragmente eines Datensatzes zusammenführen muss um diesen an den Client zurückzuführen.
Müssen sehr viele Fragmente zusammengeführt werden, wird der verteilte Datenspeicher
a) langsamer
b) benötigt mehr Hauptspeicher
c) benötigt eine viel höhere IO-Performance
benötigen, um Leseoperationen durchführen zu können. Schreiboperationen sollten hingegen immer gleich schnell bleiben, da ja jedesmal nur eine neue Version des geänderten Nachrichtenfragmentes angelegt wird.
Damit auch die Lese-Performance auf einem hohen Level erhalten bleibt, gibt es einen Mechanismus in verteilten Datenspeichern der Compaction genannt wird.
Mittels Compaction werden alle „alten“ Versionen der Änderungsfragmente mit der aktuellen Version der Änderungsfragmente zusammengeführt und die alten Fragmente entfernt.
Der Compaction-Vorgang ist jedoch, je nach Tombstone-Menge, ein sehr zeitaufwändiger Vorgang, der eine hohe Lese- und Schreib-Performance auf den Cluster benötigt. Dieser Mechanismus wird durch das Operations-Team des Clusters eingestellt.