Hot stuff - Wir bauen uns einen Cache Warmer

Wofür braucht man denn den jetzt?
In einem späteren Artikel, wenn ich den Cruncher erkläre, werden wir sehen, dass ein nicht unerheblicher Teil der Rechenlast bei der Kalkulation von Fakultäten verwendet wird.
Und wie sich noch zeigen wird, gilt der Begriff Cache-Warmer in jeder Hinsicht!
Die Fakultät (oft als n! geschrieben) ist eine mathematische Funktion, die das Produkt aller positiven ganzen Zahlen von 1 bis n berechnet. Zum Beispiel:
5! = 5 × 4 × 3 × 2 × 1 = 120
3! = 3 × 2 × 1 = 6
Die Fakultät wird oft in der Kombinatorik verwendet, um die Anzahl der Möglichkeiten zu berechnen, Elemente in einer bestimmten Reihenfolge anzuordnen. Ein Spezialfall ist 0!, das per Definition gleich 1 ist.
Verwendung:
- In der Kombinatorik, um Anordnungen und Kombinationen zu berechnen.
- In der Wahrscheinlichkeitstheorie und Statistik.
- In der Analyse von Algorithmen, insbesondere bei rekursiven Berechnungen.
Schauen wir uns die Formel zur Berechnung von Pi nach Chudnovsky noch mal an

sehen wir 3 Stellen in denen die Fakultätsberechnung angewandt wird.
(6k)!
(3k)!
(k!)³
Dabei ist k der Iterator, also der sich ändernde Teil für die Berechnung der Zwischenergebnisse.
Man kann hier jedoch sehr gut erkennen, dass
die Berechnung der Fakultät bei sehr großen Zahlen sehr aufwändig wird
im Laufe der Programmdurchführung sehr häufig die gleichen Fakultäten berechnet werden. Als Beispiel sei der Iterator 2, 6 und 12 genannt.
Iterator 2 verwendet (6*2)!, (3*2)!, (2!)³
Iterator 6 verwendet (6*6)!, (3*6)!, (6!)³
Iterator 12 verwendet (6*12)!, (3*12)!, (12!)³
Die Gemeinsamkeiten sind hier Berechnung (6 * 6)! mit (3 * 12)!, (6 * 2)! mit (12!)³, (3 * 2)! mit (6!)³
Soll heißen, alleine bei der Berechnung von Pi über 100 Iterationen sind das 300 Fakultätsberechnungen und dabei sind einige die doppelt verwendet werden.
Also warum nicht die Fakultäten zwischenspeichern um sie für die Wiederholungen schnell zur Verfügung zu haben. Dafür verwenden wir einen sogenannten Cache.
Dabei sollten jedoch 2 Überlegungen berücksichtigt werden
Wir berechnen Pi verteilt über n Knoten. Damit fällt das lokale zwischenspeichern der Fakultäten auf jedem Knoten aus, da dass die Wahrscheinlichkeit eines Cache-Treffers um 100/n % verringert.
Also bei 5 Knoten ist die Wahrscheinlichkeit eines Cache-Treffers bei lokaler Speicherung des Caches pro Knoten bei 20%.
Also ein zentraler Cache muss her!
Und was bietet sich da an? Am ehesten Redis.
Schnell, weil er als Key-Value-Store die Daten im Hauptspeicher ablegt, oder alternativ zusätzlich auch auf Disk.
Wir werden noch sehen, dass das speichern auf Disk ein wichtiger Faktor sein wird.
Wir wollen ja Pi mit möglichst vielen Nachkommastellen berechnen. Da der größte Wert in unserer Formel (6k)! ist, müssen wir bspw. bei 100.000 Iterationen die Fakultät von 1 – 600.000 berechnen. Und zwar für jeden Wert zwischen 1 und 600.000.
Versuch 1: Immer wieder von vorn und schön nacheinander
Das war eher ein Test und es war von Vornherein klar, dass der Versuch Käse ist, aber immerhin schon mal zum ausprobieren wie der Programmablauf später mal aussehen könnte.
Schlussendlich geht man iterativ von 1 – n alle Werte durch und multipliziert alle Iterationen dem vorherigen Ergebnis.
In C# gibt es dafür ein paar leckere Features die das Ganze auch noch einigermaßen funktional aussehen lassen.
Mal als Beispiel für den Wert 100:
var factor = Enumerable
.Range(1, 100)
.AsParallel()
.Aggregate(BigInteger.One, (current, next) => current * next);
Das Ergebnis ist vom Typ BigInteger. Warum?
Naja, weil das Ergebnis schon in keinen Standard-Ganzzahl-Datentyp von C# passt.
93326215443944152681699238856266700490715968264381621468592963895217599993229915608941463976156518286253697920827223758251185210916864000000000000000000000000
Aber es reicht ja nicht nur den Wert der Fakultät für 100 zu errechnen, wir müssen ja alle Werte von 1 bis 100 bzw. welchem Ende-Wert auch immer zu berechnen. Also:
for(var i = 1; i <= 100; i++)
{
var factor = Enumerable
.Range(1, i)
.AsParallel()
.Aggregate(BigInteger.One, (current, next) => current * next);
.
.
.
# Weitere Schritte
}
Aber naja, das ist ja Quatsch und macht überhaupt keinen Sinn. Teile davon können wir wiederverwenden.
Versuch 2: Schon besser, wir üben uns in Optimierung
Das Problem des vorherigen Ansatzes ist, dass die Fakultät für jede Zahl von 1 bis n immer wieder neu berechnet wird, obwohl doch eigentlich klar ist, dass bspw. die Faktultät von 6, also 6! = 5! * 6 ist und 5! = 4! * 5 usw..
Also, auf ein neues.
BigInteger cummulative = BigInteger.One;
for(var i = 1; i <= 100; i++)
{
cummulative *= i;
.
.
.
#Weitere Schritte, speichern oder sowas
}
Das ist ja einfach!
Und trotzdem total unnütz. Warum? Wir haben jegliche Parallelität aufgegeben. In Zeiten von Mehr-Kern-CPUs eigentlich ein Unding so zu arbeiten.
Allerdings wäre es fatal hier bspw. mit Parallel.For oder Parallel.ForAsync zu arbeiten, weil wir für die Berechnung des aktuellen Ergebnisses immer das vorherige Ergebnis benötigen und bei einer parallelen Verarbeitung weiß ich nicht ob für die Berechnung von 5! das Ergebnis von 4! bereits zur Verfügung steht.
Wenn man mal an richtig große Zahlenmengen denkt, dann wird schnell klar, dass einem die Parallelität an der Stelle einen Strich durch die Rechnung macht.
Außerdem wäre cummulative in exakt diesem Fall nicht thread-safe, da es sich außerhalb einer potentiellen Parallel.For… Methode befindet. Kurzum, Käse!
Versuch 3: Was nun? Viel rumprobieren und eine finale Lösung... Das muss es doch sein!
Für die Berechnung der Fakultät habe ich eine ganze Menge Sachen ausprobiert.
Von einfacher Multiplizierung innerhalb einer Schleife bis hin zu Partitionierung Zahlenreihe in verschiedene Blöcke. Schlussendlich bleibt die Berechnung der Fakultät eine Multiplikation ihrer Faktoren.
Dabei macht es immerhin Sinn die Berechnung auf so vielen Kernen wie möglich zu erledigen.
Es gibt, für Anwendung im .Net-Umfeld ein lustiges Framework.
https://github.com/dotnet/BenchmarkDotNet
Mit dem ist es, auf recht einfache Art und Weise möglich die Zeiten für Berechnungen auf unterschiedlichen Wege zu einem Ziel messbar zu machen.
Und tadaaa!
The Winner is:
ParallelEnumerable
.Range(1, value)
.Aggregate(
() => BigInteger.One,
(localProduct, i) => localProduct * i,
(totalProduct, localProduct) => totalProduct * localProduct,
finalProduct => finalProduct
)
Hier werden, in paralleler Verarbeitung, Einzelberechnungen durchgeführt und die Ergebnisse der parallelen Verarbeitungen miteinander multipliziert.
Tatsächlich war das die effizienteste Methode für die Erstellung von Fakultäten in einem Programm.
In einem Programm, aber wer sagt eigentlich dass die Fakultäten nur auf einer Maschine berechnet werden müssen?
Die Zahl Pi wollen wir ja letztendlich auch auf mehreren Rechnern (also verteilt) berechnen lassen.
Also muss ein Distributed-Cachewarmer her.
Das Ganze stelle ich mir im Grunde genommen genauso vor wie die iterative Berechnung von Pi, nur eben mit Fakultäten.
Easy as is!
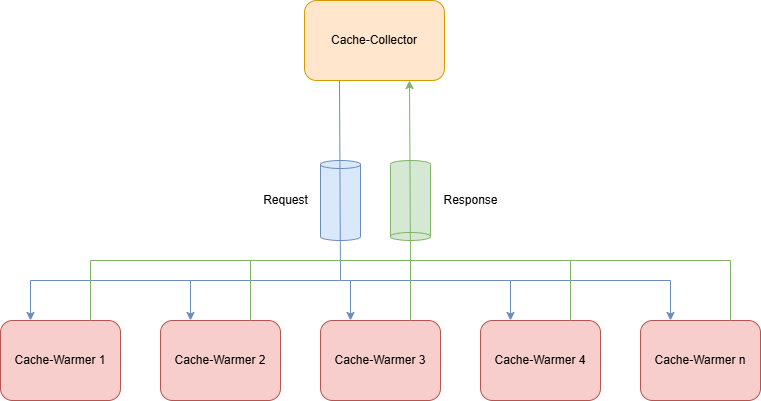
Der Cache-Collector erstellt die Requests. Dafür hat das Ding eine einfache REST-Schnittstelle, mit der ein Start- und ein Endwert angegeben werden können. Also irgendwie sowas hier.
curl -X PUT http://192.168.0.100:9011/calculation/start -H "Content-Type: application/json" -d '{"StartValue":200000, "EndValue": 300000}'
In einer Fire- and Forget-Methode erzeugt der Cache-Collector die Request und packt alles in ein Request-Topic. Die Cache-Warmer nehmen sich die Requests heraus berechnen die Fakultät und schreiben das Ergebnis in ein Response-Topic. Der Cache-Collector nimmt das Ergebnis aus dem Response-Topic und schreibt das weg.
Dabei gibt es aber ein paar Dinge zu beachten, die mir im Laufe der Implementierung aufgefallen sind.
- Für den Transport des Ergebnisses ist die einfachste Art eine Serialisierung in JSON. Das ist aber fatal, da JSON (bzw. Javascript) per default solch große Zahlen nicht unterstützt. Also müsste das Ergebnis als Text umgerechnet werden. Hier reicht aber eine einfache Rechnung um das Problem zu verdeutlichen. Nehmen wir mal eine sehr kleine Fakultät z.B. 30! Das Ergebnis ist 265252859812191058636308480000000. Irgendwie albern, aber die Bit-Interpretation ist 110100110001101111001101010000101011100101001100100000010000000110010011000010111010010001011000111111111010000000000000000000000000000000000000 (119 Bit). 119 Bit / 8 (wegen byte und so) = 15 (also eigentlich 14,8 aber es wird immer auf das nächste Byte aufgerundet). Also, letztendlich übertragen wir als Text mindestens 36 Byte und als Binärwert 15 Byte. Und 30! ist noch niedlich. Da kommen noch ganz andere Werte.
- Früher, da gab´s mal in meiner favorisierten Programmiersprache einen Binärtformatter. Der hat aus allem möglichen die Binärinterpretation und vise versa gemacht. Das Teil gibts aber nicht mehr wegen Sicherheitsproblemen (oder ist aus dem .NET-Core Standard rausgeflogen). Hier bietet sich Messagepack (https://github.com/MessagePack-CSharp/MessagePack-CSharp) an. Das Teil wandelt in Objekte in Binärcode um und zurück. Optimalerweise hat das Teil auch gleich noch LZ4 Kompression implementiert. Fertig.
- Jetzt kommen die Pakete beim Cache-Collector an und müssen ja nun irgendwo gespeichert werden. Als Binärformat ist kein Problem und am Anfang dachte ich dass Redis hier eine gute Wahl ist. Dachte ich! Warum? Alleine die Fakultäten von 1-200.000 sind optimiert gespeichert 38.6 GByte. Schlussendlich hat das beim mir dafür gesorgt, das ab 12 GByte Datenvolumen Redis einfach kaputtgegangen ist und selbst die Redundanz auf Disk weg war. InMemory ist halt irgendwann Käse.
- Daher habe ich mich dazu entschieden Minio für die Speicherung der Fakultäten zu verwenden. Die Werte im Bucket werden als Binärwert abgelegt, wass es ermöglicht die Werte aus Kafka direkt (als byte[]) in den Store zu schreiben, ohne nochmal eine Umwandlung vornehmen zu müssen.
Aber, aber, aber…
Aber letzt- und schlussendlich
Grau ist alle Theorie und manchmal verstrickt man sich in komplexe und komplizierte Lösungen die „letztendlich“ funktionieren, aber was Effizienz betrifft „schlussendlich“ Mumpitz sind.
Warum?
Schauen wir uns die Logausgabe mal an, sieht man ziemlich deutlich was das Problem ist.
Der Cachewarmer funktioniert ja, in dem die Fakultät von n berechnet wird durch die Prüfung ob n – 1 bereits im Cache (Objectstore) liegt. Wenn ja, wird das Ergebnis geholt und einfach der Wert aus n – 1 mit n multipliziert wird.
Wenn nicht, naja, wird von 1 – n die Fakultät gebildet.
Nachfolgender Screenshot demonstriert das Problem.
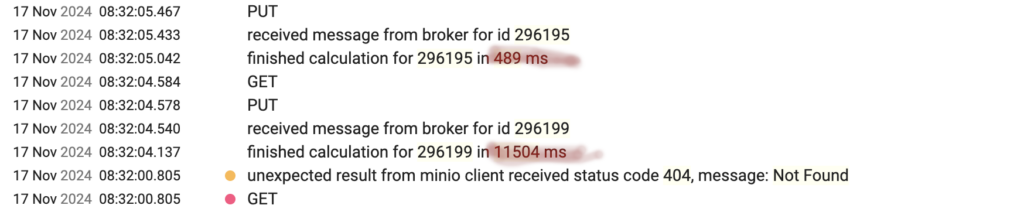
Das ganze Cache-Geprüfe usw. funktioniert in der verteilten Welt nicht so gut, weil, wie im Falle der Logausgabe ersichtlich, eine Neuberechnung der Fakultät, da ja offensichtlich der Vorgänger noch nicht im Cache liegt, so lange dauert (Faktor 23), dass es einfacher ist, die ganze verteilte Berechnung und Parallelität über den Haufen zu werfen und alles in einer guten alten Schleife ohne Firlefanz berechnen zu lassen. Dafür braucht es weder einen Docker-Container noch Kafka nur damit es hipp aussieht.
Das Hauptproblem besteht halt darin, dass eine Berechnung von 1-n (im Falle der Logausgabe ist n=296.199) eben 296.198 Iterationen sind, Während 296.198 * 296.199 eben genau 1 Iteration ist. Und die eine Multiplikation ist hierbei extrem billig.
Also verteilen ja, aber eben nicht verteilt im Sinne von mehreren Rechnern, sondern tadaaa…
Wir nutzen effektiv ein vorhandenes Multicore-System zur (core-) verteilten Berechnung von Fakultäten. Wie?
Na ganz einfach! Kennt noch jemand eDonkey oder Napster? Genau! Dort wurden die einzelnen Dateien in viele Häppchen geteilt und in sogenannten Chunks heruntergeladen. Am Ende, wenn alle Chunks zusammengesetzt waren, war die Datei heruntergeladen.
Genau das machen wir in der finalen Lösung. Wir erzeugen eine Range von 1 bis 1.000.000 und teilen diese in Chunks (Blöcke) á 1.000 Werten. Jeder Chunk wird parallel, im Beispiel 14, Tasks zugewiesen und abgearbeitet. Der erste Wert des Chunks wird immer „per Hand“ berechnet (also iterativ von 1 bis Chunk.First) und alle weiteren Werte des Chunks werden immer um den nächsten Wert weiter multipliziert und das Ergebnis nach Minio übertragen und gespeichert.
Thats it, nothing more, nothing less.
var cfg = new SimpleMinioConfiguration("Minio-Url", "Minio-Access-Key",
"Minio-Secret-Key");
var minioClient = new SimpleMinioClient.SimpleMinioClient(cfg);
var startValue = 1;
var endValue = 1000000;
var partitionSize = 1000;
var range = Enumerable
.Range(startValue, endValue - startValue + 1)
.Chunk(partitionSize);
await Parallel.ForEachAsync(range, new ParallelOptions { MaxDegreeOfParallelism = 14 }, async (chunk, token) =>
{
BigInteger cacheValue = new();
for (var i = chunk.First(); i <= chunk.Last(); i++)
if (cacheValue == BigInteger.Zero)
{
cacheValue = ParallelEnumerable.Range(1, i)
.Aggregate(
() => BigInteger.One,
(localProduct, i) => localProduct * i,
(totalProduct, localProduct) => totalProduct * localProduct,
finalProduct => finalProduct);
var ms = new MemoryStream(cacheValue.ToByteArray());
Console.WriteLine($"{DateTime.Now:yyyy-MM-dd HH:mm:ss.fff} :: First value {i}");
await minioClient.PutObjectAsync("factorials", $"fac_{i}", ms);
}
else
{
if (i % 100 == 0)
Console.WriteLine($"{DateTime.Now:yyyy-MM-dd HH:mm:ss.fff} :: Next value {i}");
cacheValue *= i;
await minioClient.PutObjectAsync("factorials", $"fac_{i}", new MemoryStream(cacheValue.ToByteArray()));
}
});
Das Problem ist jetzt...
…definitiv nicht mehr die Kalkulation der Fakultäten mittels Multi-Core-CPU, sondern schlicht und ergreifend Netz- und Disk-IO. Starte ich den obigen Code auf meiner Workstation mit 32 Cores mit insgesamt 30 Tasks, überlaste ich ein 2.5GBit Netzwerk zum einen und zum anderen bekomme ich ein Problem mit dem Minio-Storage. Das liegt nämlich nur als Single-Storage-System vor. Die dauerhaften 2.5GBit (oder ca. 300 MB/s) wollen auch auf SSD erst mal weggeschrieben werden.
Irgendwas ist immer langsam!
Fazit!
Manchmal ist einfach eben doch mehr. Bewahrheitet sich in den o.g. Beispielen sehr deutlich.